앞서 살펴봤듯이 RISC-V Instructions들은 보통 아래 다섯가지 steps으로 구현된다.
1. IF : Fetch instruction from memory
2. ID : Read registers and decode instruction
3. EX : Execute operation or calculate address (← ex. ALU 쓰는 부분)
4. MEM : Access an operand in data memory
5. WB : Write the result into a register

> Single Cycle execution

우리가 이전 글에서 만들었던 single clock cycle 버전은 위처럼 돌아간다. 한 instruction을 clock 한번내에 단계별로 진행한다. 단점은 instruction마다 모든 단계가 다 진행되는 것은 아니라서 위처럼 시간 낭비가 있을 수도 있다. single cycle 버전에서는 가장 긴 path에 맞춰서 cycle을 정하기 때문에 저렇게 단계를 진행 안하는 좀 짧은 path라면 잠시만 기다려야한다.
어근데 Multi Cycle이더라도 결국 저렇게 아무것도 안하고 낭비하는 부분은 있는데?
: ㅇㅇ 그런듯?? Multi Cycle이여도 저렇게 수행안하는 단계가 있더라도 어차피 그 단계에 한 cycle을 쓰긴 해야한다. 그러니 Single cycle의 단점은 그냥 지난 글 마지막에 말한 것을 보면 될듯. "pipeline이 없이 보면" Multi나 Single이나 가장 긴 path에 맞춰야돼서 문제있는건 비슷..
여기서 말한건 이전 글 마지막에 말했듯이 "그냥" clock을 가장 긴 path에 맞춰야하니까 저런 낭비가 생간다는게 포인트인듯.
> Multi Cycle execution

이전 글 마지막에서 봤지만, Single Cycle 버전은 잘 쓰지 않고, 위와 같이 Multi Cycle 버전을 만든다.
한 Clock에서 한 step만 처리하도록 하는 것이다. Clock에서 하나의 step만 처리하므로 clock cycle이 훨씬 짧아진다.
> Pipelined execution

multi cycle 버전을 더 효율적으로 변경한 것이다. 단계를 clock마다 처리하도록 나눴기때문에 놀고 있는 놈들이 있으면 분업할 수 있다.
위 경우를 보면 state가 5개이므로 instructions을 5개까지 한번에 실행할 수 있다.
> Pipeline Performance
(복습하고 가자면, throughtput은 단위시간당 작업처리개수이다. 아래에선 그 "작업"을 instruction으로 본다.)
Theoretic throughput improvement = N of pipeline stages
이론상 stage 개수가 늘면 그 늘어난만큼 그대로 쓰루풋도 증가한다. stage가 5개면 한번에 5개씩 처리할 수 있고, 6개면 6개씩 처리할 수 있고.
Time-between-instructions_pipelined = Time-between-instructions_nonpipelined / N of pipeline stages
pipeline이 적용되지 않은 경우의 instructions간 시간차는, N개의 pipeline stages가 적용되면 1/N만큼 줄어든다.
기존에 instruction 하나의 수행시간이 K였다고해보자. 그럼 pipeline이 없을때 두 instructions간 수행시간 차이는 K이다.
N개의 pipeline stages가 여기에 적용된다면, 한 instruction 수행시작 후 K/N이 지났을때 다른 instruction을 실행시킬 수 있게된다. 즉 두 instructions간 시간차이는 1/N이 되는 것이다. 단, 이론상 이란 것을 주의해야한다.
Q. 그럼 stage를 무한대로 늘리면 엄청 빨라지는게 아닌가?
A. 위 식은 이론적인 수치이다. 바로 아래에서 보겠지만, 1/N씩 극적으로 빨라지진 않는다.
그리고 애초에 stage를 더이상 논리적인 단계로 나누기가 어려워서 더 작은 stage로 쪼개지도 못한다.
또 pipeline stage는 모두 관리돼야하는데, 그게 늘어나면 통제 logic이 많이 필요하고, 복잡도가 올라가서 성능에 악영향을 끼칠 가능성이 높다.
그래서 2010년대 들어선 이후로는 거의 14-20개 정도의 stage가 사용되고 있다.

5개의 각 step이 위 표만큼 시간을 소모한다고 했을때 pipeline의 성능을 직접 계산해보자.

Single-Cycle인 경우이다.
clock cycle은 가장 긴 path(이경우 ld)에 맞춰지므로 무조건 800ps이다. Clock cycle이 800ps이므로 Branch든 R-format이든 실제로 필요한건 500, 600ps지만 800ps만큼 걸릴 수 밖에 없다는 것을 주의해야한다.
그래서 총 걸린 시간은 간단하게 "instructions개수 x 800ps"로 구할 수 있다.

이번엔 Multi-Cycle이면서 pipeline도 적용된 경우이다.
이 경우도 clock cycle을 가장 긴 path(step)에 맞춘다는건 변함없다. 차이는 clock cycle을 하나의 instructon에서 보는게 아니라 각 step 별로 봐야한다는 것이다. 가장 긴 step에 모든 step이 맞춰져야하니 한 step의 clock cycle은 200ps이다.
Reg(ID)도 실제론 100ps이지만 clock cycle은 200에 맞춰진다는 것을 주의해야한다.
어쨌든 위 세 instruction을 수행하는데 걸리는 총 시간은 200+200+200x5 ps = 1400ps이다.
얼핏봤을때, 한 instruction의 수행 시간이 총 800ps에서 1000ps로 늘어난다, 오히려 instruction 하나에 대한 수행시간은 길어진 것이다.
이게 손해로 보일 수도 있지만,
throughput이 증가했으므로 전체적으론 빨라졌다. 하지만 이론상으로 봤던 1/5 수준은 아니다.
pipelined 버전에서 R type이라면 Data access 같은 부분은 필요없으니 좀 더 빨리 될 수도 있겠다는 생각이 들긴하는데,
아니다. R-type이여도 전체 inst를 수행하는데는 1000ps가 걸린다. Data access는 R-type에선 필요없는게 맞지만, pipeline이 쭉 유지되려면 그 단계도 무조건 거쳐야한다. 즉, 본인이 수행하지 않는 stage에선 아무것도 하지 않을 뿐, 해당 stage를 지나가긴하므로 어느 instructions이든 5개 stage를 모두 수행하는 것 처럼 그려진다.
참고1.
pipelined 버전에서 보통 계산할때 앞에 200ps 두개는 딱히 생각을 안한다. 보통 inst.는 몇백만개 몇억개 수준이라서 앞에 400ps 정도는 무시하는 것이다. 그래서 instructions이 (꽤 큰) n개라면 n x 200ps로 보통 계산한다.
참고2.
1000ps == 1ns
Pipeline Hazards
Pipeline에서 Hazards란, 다음 instruction이 next cycle에서 곧바로 실행될 수 없는 경우를 말한다.
(위에서 봤던 경우들은 아무 문제 없이 잘 수행되는 경우들이다.)
Hazards에는 아래 3가지 유형이 있다. 여기선 좀 간단하게 보고, 아래에서 자세하게 모든 경우를 본다.
1. Structural Hazards
H/W의 구조적 문제로 인해서 발생하는 경우이다. resource conflict가 발생하면 특정 instructions들을 동시에 수행할 수 없을 수도 있다.
예를들어 이전 글에서 만들었던 single cycle 버전은 IM과 DM이 나눠져있어서 문제가 없었는데, 만약 둘이 분리되지 않은 하나의 메모리로 구현됐다면 문제가 될 수 있다. 왜냐하면 메모리가 하나로 합쳐지면 IF와 MEM 단계에서 "한" memory에 접근하게 되므로, 여러 instructions에서 동시 접근하여 문제가 생길 수 있다.
해결법은 간단하다, 그냥 필요한만큼 H/W를 추가투입해주면 된다.
2. Data Hazards
다음 instruction에서 필요한 data가 아직 준비되지 않은 경우이다. 두 inst.간 data dependency가 있어서 발생하는 문제이다.
예를들어,

이라고 할때 sub는 add 다음에 바로 따라올 수가 없다. x1은 add가 끝나야 값을 알기 때문이다.
참고로, 이때 x1이 앞 inst.에서 rd(writing 당하는 대상)이기 때문에 문제(dependency)가 되는 것이다. add x2, x1, x3 이었다면 문제될게 전혀 없다.
Data Hazards 해결법: (1)Stall

data hazard를 해결하기위해서 간단하게 add가 끝날때까지 sub의 실행을 잠시 멈추면 된다.
근데 꼭 add가 다 끝나고 sub를 실행할 필요는 없고, sub의 EX에 들어가기 전까지만 값이 준비되면 된다. 위 그림에서 보자면 registers의 값을 가져오는게 ID 단계이므로 sub의 ID로 값을 가져오기전에 add가 WB를 완료해서 register에 작성을 마쳐야한다.(일단은 ID전에 WB가 오는게 맞긴한데 아래 "참고" 보면 둘이 같이 와도 됨. 그렇게해도 sub의 EX에 (준비된) 값이 제대로 들어감.)
그러니 sub의 ID가 add의 WB가 같이 오도록(왜 같이 오나? ID가 뒤에와야지?→아래 참고 볼 것) Bubble을 두개 넣어준다. Bubble이 들어가는 두 cycles 동안은 stall(wait)된다.
※참고
위 해결방법에서 WB와 ID가 동일선상에 있을때를 한번 주목해보자.
이때 add의 WB 작업과 sub의 ID 작업 모두 같은 register file에 동시에 접근하게되므로, "add의 WB가 끝나야 sub의 ID에서 데이터를 읽어올 수 있으니 동시 처리하면 안되지 않나" 생각할 수도 있는데, 그 부분을 한번 자세히 보자.
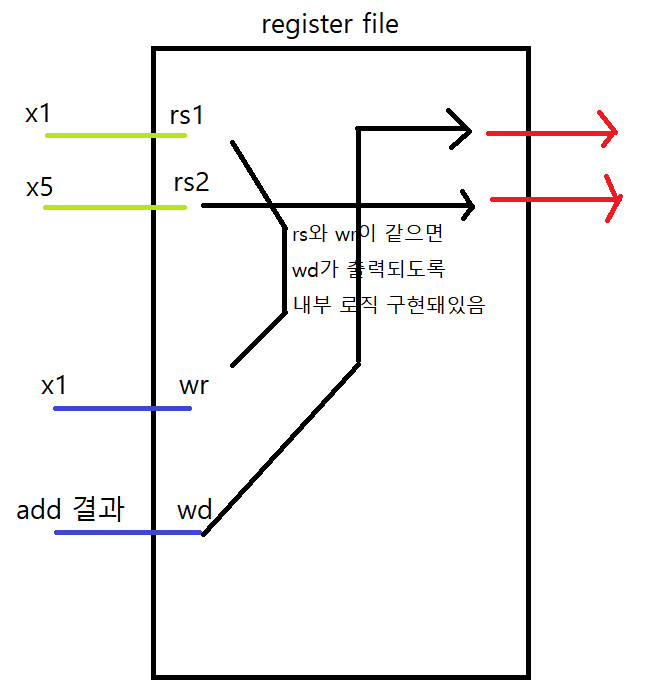
말했듯이, add의 WB 작업과 sub의 ID 작업 모두 같은 register file에 동시에 접근하게된다.
위 그림을 보면, 초록색과 파란색으로 WB와 ID에서 동시에 접근한 경우를 보여준다.
초록색이 ID에서 넣어주는 register이고, 파란색이 WB에서 쓰기위해 접근한 부분이다.
register file에는 내부적으로 rs와 wr이 같으면 해당 출력부분은 wd가 나오도록 내부로직이 구현돼있다. 따라서 add에서 더한 결과인 x1의 값을 sub에서 잘 가져올 수 있게 된다.
Data Hazards 해결법: (2)Forwarding
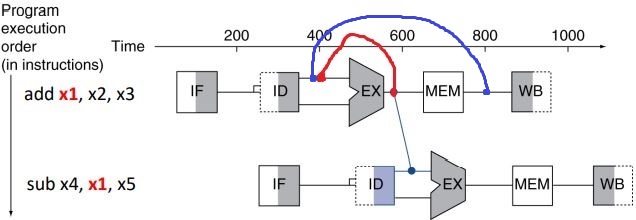
위는 data hazards의 해결법 중 하나인 Forwarding이라는 방법이다.
bubble을 넣지않고 그냥 EX의 결과를 뒤로 보내주는 방식이다. 왜냐하면 사실 이미 EX 단계에서 x1의 값은 나오기때문에 걔를 바로 토스해주면 된다. 여기선 EX의 결과를 Forwarding한다.
이렇게 하면 한 cycle도 낭비하지 않고 Data hazards를 해결할 수 있다.
(위 아래 H/W는 같은 H/W이므로 사실 빨간 색 선처럼 연결된다.)
R-type instructions이 위처럼 바로 다음에 오지 않고, 다음다음에 올 수도 있다.
이 경우까지도 Data hazard인데, 이땐 파란색 선처럼 MEM의 결과를 forwarding 해와야 한다.
그런데 아래 예시를 보자. Load-Use Data Hazard 라는 경우이다.
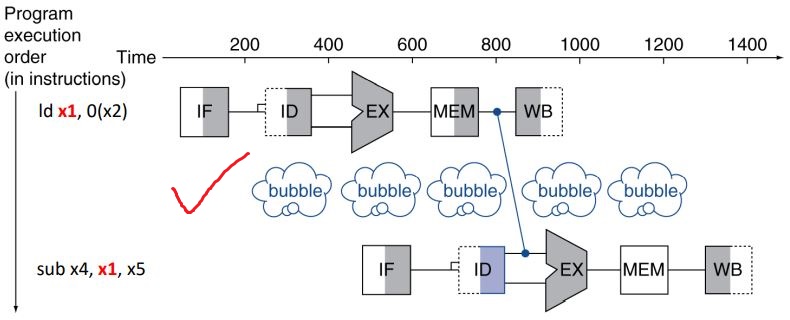
이렇게 load instruction 다음에 R-type instruction이 오는 경우를 load-use data hazard라고 한다.
이 경우에는 WB가 아닌 MEM까지 갔다와야하므로 MEM의 결과를 "곧 바로" Forwarding해와야한다. 그래서 두 단계가 차이나므로 stall(bubble)을 피할 수 없다.
Q. 일반 data hazard에서도 type2면 두단계 차이나지만 forwarding하면 해결 되는데? 얘는 왜 두단계 차이난다고 무조건 stall이지?
A. load-use data hazard의 경우 곧바로 forwarding 해와야 한다는 것 때문에 그렇다. 위에선 곧바로 오는 instruction이 아니라 한번 건너뛰고 오는 instruction이었기때문에 forwarding을 해주면 해당 값을 잘 받아올 수 있었지만,
load-use 인 경우 위에서 언급한 forwarding을 해줘도 stall을 해줘야 제대로 작동한다는 것이다.(hazard는 아래에서 다시한번 자세하게 다룬다.)
하지만 위에 빨간색으로 표시해둔 bubble에 위 아래 두놈과 영향을 주고 받지 않는, 무관한 instruction을 돌려버리면 cycle 손해를 안봐도 된다.
Data Hazards 해결법: (3)Code Reordering
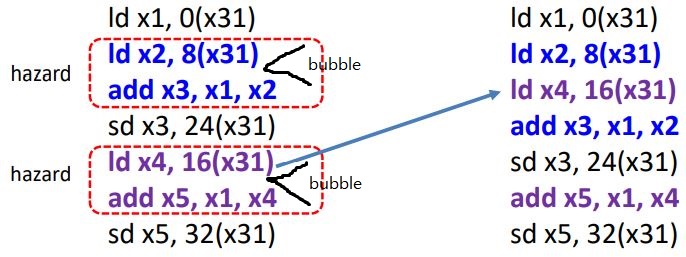
Code Reordering이란.
bubble이 발생할 위치에 위아래와 무관한, dependency가 없는, 먼저 수행해도 괜찮은 다른 instruction을 돌리도록 code를 재배치하는 것이다.
위 경우도 ld x4, 16(x31)이 먼저 실행해도 문제가 없는, dependency가 없는 놈이라서 bubble 위치에 재배치 할 수 있다.
따라서 왼쪽은 hazards가 두번이나 발생해서 2 cycles을 손해보지만, 오른쪽은 cycle 손해가 전혀 없다.
(이런 재배치 작업은 보통 compiler 같은데서 해준다.)
아무나 저 위치에 끼일 수 있는건 아니라서 항상 reordering이 가능한건 아닐 수도 있지만, 'load-use data hazards의 피할 수 없는 bubble'을 사실상 거의 다 없애줄 수 있다.(순서 상관없는 independence한 놈 아무나 가져오면 되는데 거의 다 그런 놈이 하나씩은 있기때문...)
그리고 굳이 위 예시처럼 load-use가 아니더라도 의존성 있으면 reordering으로 일단 없애주고 회로에 넣을듯.
3. Control Hazards (= Branch Hazards)
이전 instruction의 결과가 다음 instruction의 실행 순서에 영향을 미치는 경우이다.
branch문이 나온다면, 그 다음으로 들어올 instructions은 점프할 곳인지 바로 다음 instructions인지 미리 알고 넣을 수는 없다.
즉, 최소 이전 instruciton의 EX stage가 끝나야 다음 instruction이 무엇인지 알 수 있다.(회로보면 MEM이 끝나야하긴함)
Control(Branch) Hazards 해결법: (1)Stall
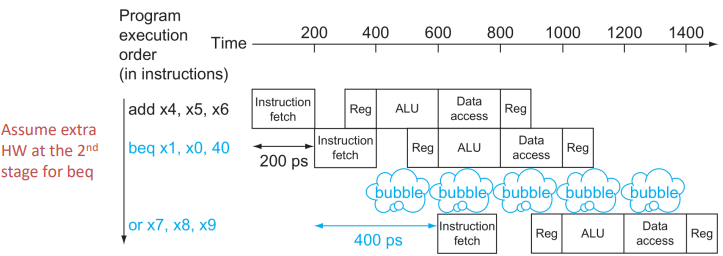
가장 간단한 방법은 MEM stage가 끝날때까지 stall하는 것이다.(아래 회로도보면 MEM stage에서 branch 판단을 해서 MEM 끝날때까지 기다려야 한다.)
뭐 어쨌든 bubble이 실제론 세개가 필요하지만 H/W 최적화로 bubble을 하나밖에 넣지 않았다.(나중에 자세히 알아봄)
Control(Branch) Hazards 해결법: (2)Prediction
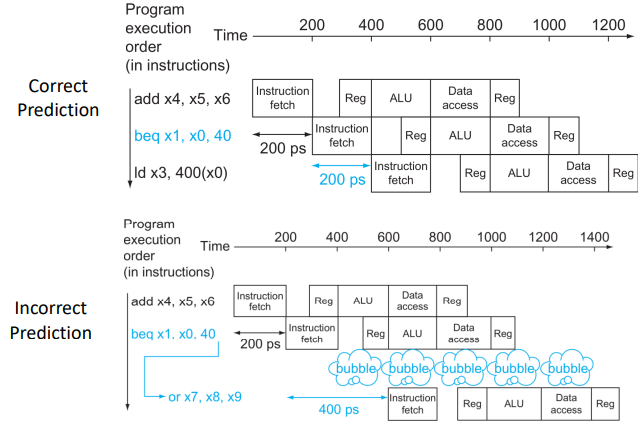
두번째 방법은 prediction이다. prediction은 Static(Simple) prediction과 Dynamic prediction으로 나뉜다.
예측을 해서 맞으면 이득이고, 틀리더라도 본전이기때문에 일단은 시도하는 것이 이득이다.
우선 Static Prediction에 대해 알아보자. Static은 execution전에 모은 정보로 branch taken/untaken 중 하나로 정하고 계속 그 예측을 사용하는 방법이다. (책에서는 NotTaken을 가정한다.)
branch 예측은 보통 skewed이기때문에 확률이 높은 쪽으로 찍으면 좋다. 예를들어 for문같은걸 봐도 for문 마지막에 들어가는 branch는 반복횟수만큼 branch taken을 하다가 마지막에 한번 untaken을 한다. 이렇게 한 프로그램에서 branch 결과는 보통 편향돼있으니 편향된 쪽으로 예측을 한다면 더 유리할 것이다.(predictions이 1%라도 성공하면 안하는 것에 비해 이득이긴 할 것이다.)
(typical behavior에만 의존한다.)
다음 Dynamic Prediction은 runtime 중에 모은 정보로 다음을 예측하는 방법이다.
그렇다고해서 CPU가 엄청 빨리 도는 와중에 매번 fancy한 예측 작업을 할 순 없고(그럼 전체적으로 발생하는 penalty가 상당할 것임), 빠르게 모을 수 있는 정보로 간단하게 (대충) 예측을 한다. 그럼에도 최대한 정확하게 하는 것이 관건이다.(현대 CPU들은 거의 90% 이상의 정확도를 보인다.)
예를 들어보자.(수업에서 든 dynamic prediction하는 예시인데, 다른데선 다른 방법 쓰려나,, 모르겠네)
보통 최근 branch decisions에 따라 count해두고 그 기록을 다음 branch prediction을 위해 사용한다.
그러기 위해 branch instructions을 기록하기위한 table이 우선 하나 필요하다.
그 다음, branch inst가 나오면 해당 inst의 주소의 LSB n 비트를 이용해 table을 조회한다(table은 해싱개념으로 작동). table의 count 값이 "MSB만 보고" 양수라면 branch를 하고 음수라면 branch를 하지 않는다.
그리고 해당 branch inst의 결과를 table에 반영한다. taken이라면 해당 카운트를 증가시키고, not-taken이라면 해당 카운트를 감소시킨다.
(허점이 있어보인다. LSB n-bit로만 판단하면 내가 한 branch가 아닌데도 같은 곳에 매핑돼서 그 결과를 쓰게 될 수도 있다. 또 MSB로만 체크하는 것도 애매하다. 하지만 위에서 말했듯이 같은 곳에 매핑되거나 하는 정도는 그냥 감수한다. CPU는 당장 inst를 돌려야 하므로 이보다 fancy한 작업을 할 수는 없다.)
Static이 overhead는 적지만, overhead가 비교적 큰 Dynamic에 비해 예측이 좋지 못할 수 있다.
위 그림에서 볼 수 있듯이 prediction이 성공하면 이득이지만, 실패해도 stall과 똑같이 bubble이 하나 추가되므로 본전이다. 예측을 잘못한 대가로 1cycle이 낭비됐다고 볼 수도 있겠다.
(여기도 마찬가지로 bubble이 하나만 생긴다고 일단 알자. 자세한건 뒤에서...)
Control(Branch) Hazards 해결법: (3)Extra H/W
뒤에서 자세히 다룬다.
Pipelined Datapath
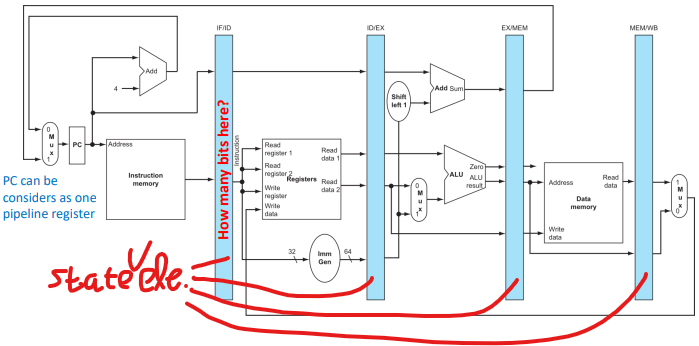
위 그림은 pipeline이 적용된 Datapath이다. 각 단계들 사이에 state element인 registers를 배치시킨다. 얘네를 pipeline register라고 한다. state element이므로 각각에 clock도 꼽혀있다. PC도 그냥 pipeline register 중 하나로 볼 수도 있다.
각 pipeline registers는 stage들의 중간 결과를 저장하며, registers의 크기는 이전 결과(와 control 신호)를 저장할 만큼"만" 있으면 되기때문에 각자 다르다.(H/W 최소화를 위해 필요한 만큼만 할당해준다.)
(밑에 나오는데, 각 pipeline register에는 이전 결과 뿐 아니라 control 신호도 저장된다.)
각 pipeline registers의 이름은 "IF/ID"처럼 양옆 stage의 이름을 사용해 지어준다. (IF/ID에 담겨있는 instruction은 현재 ID stage를 진행중인 것이다.)
그럼 이제 각 pipeline registers가 stages를 분리해주는 꼴이니 clock이 튈때마다 다음 stage가 진행되는 것이다.
(ld, sd가 어떻게 진행되는지 한단계씩 보고싶다면 강의자료 ppt 참고)
하지만 위 datapath는 bug가 있으니 아래와 같이 변경해야한다.
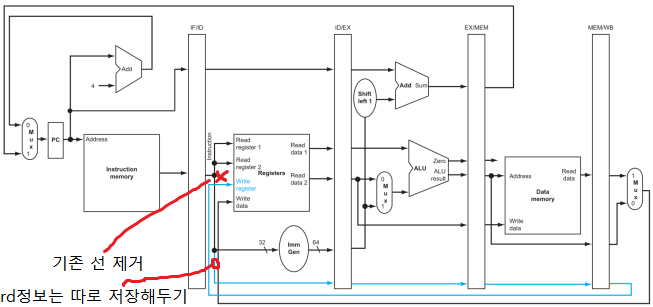
이렇게 변경해야하는 이유는, register file에 write하는게 제대로 작동하지 않기 때문이다.
위쪽 그림대로면 write register를 할때쯤엔 이미 해당 stage엔 다른 instructon이 수행중이다. 즉, 엉뚱한곳에 write을 하게 될 것이다.
따라서 위 그림과 같이 write register 정보를 pipeline register을 통해 계속 같이 가져가다가 마지막에 쓸때같이 써줘야한다.
(기존 선은 없애는게 맞다. 그 선에 나오는 rd 정보는 pipeline register에 저장해야한다. wirte하는 시점에선 그 선이 필요없다.)
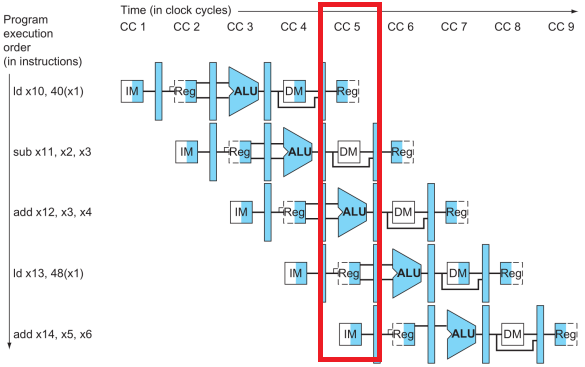
위는 각 instructions 특정 clock에 어떤 resource를 사용하는지 보여주는 그림이다.
특정 순간에서 pipe line의 상태를 보려면 빨간 박스처럼 세로로 보면 된다.
색칠된게 수행되는 부분이다. 자세하게 보면 Reg는 ID에선 오른쪽 반이 색칠되고, WB에선 왼쪽 반이 색칠된다.
위에서도 말했지만 R-type이든 뭐든 모든 instructions은 5개 stage를 모두 수행은 한다. 따라가기만하고 아무것도 안하는 stage는 아예 흰색으로 색칠돼있다.
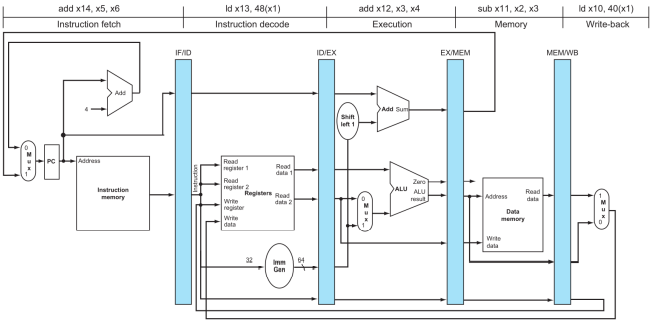
이 그림은 특정 clock일때를 Datapath HW 상태를 보여주는 것이다. 각 stages마다 instructions을 제각각 수행중이다.
Pipeline Control
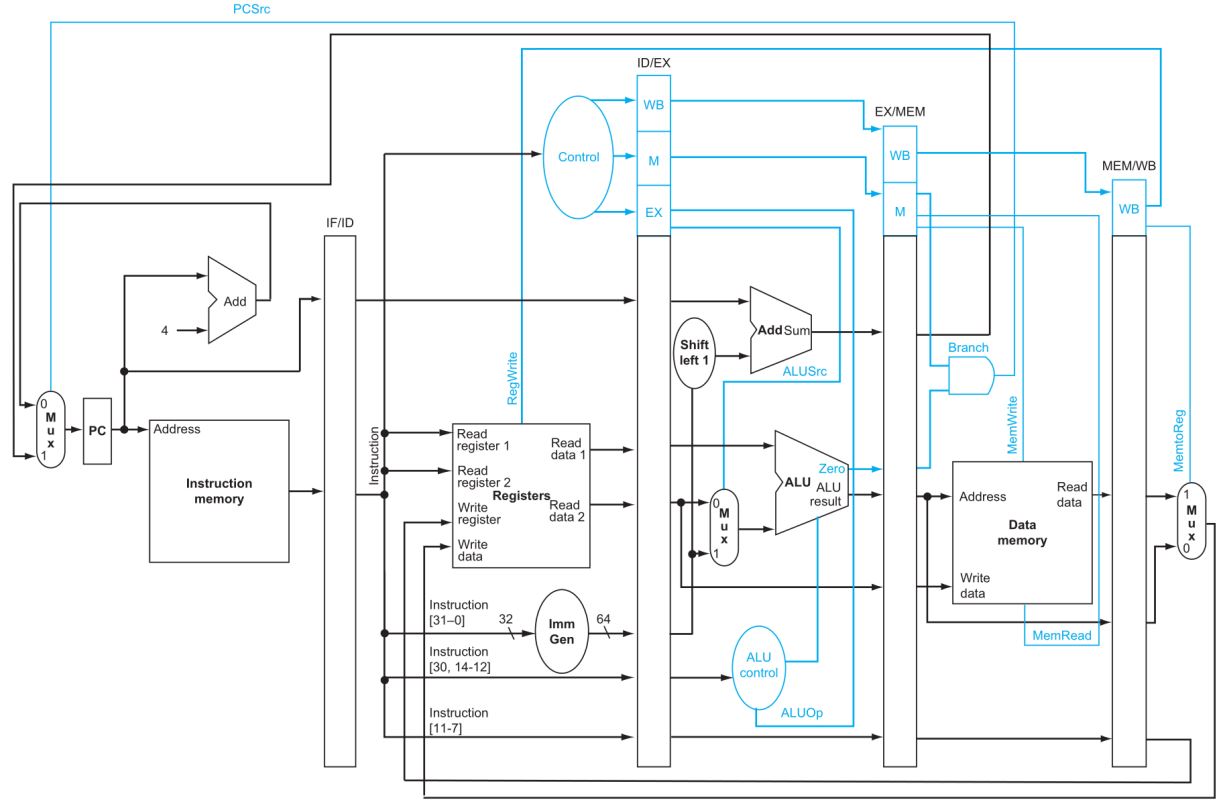
Control 신호도 기존에 배운 것과 크게 다른 것은 없다.
하나 다른게 있다면, (파란 색으로 표시된 부분에) ID stage에서 생성된 Control 신호는 ID/EX pipeline register에 저장된다는 것이다.
위에서 우리가 rd를 계속 가지고 갔듯이, Control 신호도 매 pipeline register에 같이 저장해서 가지고 가야한다. Control이 필요한 stage에서 Control을 주고 해당 공간은 pipeline register에 지우는 방식으로 쭉 진행된다.
또 하나 짚을 점은 pipeline register는 write signal이 없다는 것이다. 왜냐하면 매 클럭마다 write는 무조건 이뤄지기때문에 굳이 따로 신호를 두진 않는다. (PC도 같은 이유로 write signal이 없는 것이다.)
기존 Datapath와 pipeline 버전이 다른 점은
(1) 중간에 pipeline register가 들어와서 중간결과 저장하는 것
(2) rd나 Control 신호는 필요한 순간에 꺼내쓸 수 있게 ID에서부터 매 pipeline registers에 저장해야된다는 것
이다.
Q. Pipelined Datapath with Control에서 EX stage의 ALU 의 Zero 신호는 왜 다시 EX/MEM에 저장하는 것일까?
EX stage Adder 결과도 마차가지다. 둘 다 그냥 바로 PC를 결정하는 회선으로 연결되면 되지않나? 왜 MEM에서 둘을 AND해서 PCSrc로 보내는거지? 바로 처리하면 branch hazard로 인한 stall 줄일 수 있을텐데?
A. 그렇게 해버리면 EX stage를 처리하는데 시간이 오래걸린다. clock cycle은 가장 긴 stage에 맞춰지므로 전체적으로 느려지게 되는 것이다. EX stage에는 이미 연산이 있는데 병렬도 아니고 "순차적으로 추가 연산(AND와 그 이후 MUX까지)"을 진행하면 당연히 시간이 "더" 걸린다. 따라서 MEM에서 MEM의 기존 작업과 병렬로 처리할 수 있게 설계하면 전체적으로 시간 손해를 덜 보는 것이다.
Control 신호 부분을 쪼끔 자세히 보자면, 우선 ID/EX register에는 모든 7개 신호가 다 저장된다.
그리고 아래 표와 같이 각 stage에서 신호를 몇개씩 꺼내쓴다(?). EX/MEM에는 그래서 5개 신호만 저장되고, MEM/WB에는 2개 신호만 저장된다.

위에서 pipeline hazards에 대해 간단하게 알아봤었다. 여기선 좀 더 자세하게 실제 회로도 함께 본다.
들어가기전에 알아야할 notation이 하나 있다.
ID/EX.RegisterRd 라고 표현한다면, ID/EX pipeline register에 저장된 data 중 RegisterRd 데이터를 특정해서 말하는 것이다.
1. Data Hazards
Data Hazards에는 총 네 종류가 있다.
1. type 1a (다음 줄의 첫번째 rs와 dependency)
2. type 1b (다음 줄의 두번째 rs와 dependency)
3. type 2a (다다음 줄의 첫번째 rs와 dependency)
4. type 2b (다다음 줄의 두번째 rs와 dependency)
예를들어 다음 코드가 있다면, and와 or은 각각 type 1a와 type 2b이다.
아래 add와 sw도 sub에 dependency가 있긴하지만, Data Hazards는 아닌 것이다.
왜냐하면 3칸 이상 차이가 나는 dependency인 경우, 예를들어 sub의 WB와 add의 ID는 같은 clock에 진행되기때문에 위에서 봤듯이 register file에서 잘 처리해주니까 전혀 문제가 없다.

위에서 봤듯이 이런 Data Hazards는 Forwarding으로 깔끔하게 처리할 수 있다.(load-use여도 버블 하나면 됨)
그런데 Forwarding을 하려면 일단 Data Hazard인지 탐지를 해야한다.
Dependency Detection은 어떻게 할 수 있을까?
총 세단계를 만족하면 Detect된다.
1. 가장 기본은 당연히 rd와 rs1, rs2가 같은지 보는 것이다. 즉 아래 네가지 경우 중 하나라도 만족하면 data hazard가 발생한 것이다.
type1a: EX/MEM.RegisterRd = ID/EX.RegisterRs1
type1b: EX/MEM.RegisterRd = ID/EX.RegisterRs2
type2a: MEM/WB.RegisterRd = ID/EX.RegisterRs1
type2b: MEM/WB.RegisterRd = ID/EX.RegisterRs2
왜 뒤의 inst가 EX stage까지 가서야 detect를 하는걸까? EX/MEM.RegisterRd랑 ID/EX.RegisterRs1을 비교하지말고 ID/EX.RegisterRd랑 IF/ID.RegisterRs1을 비교하면 되지않나?
: 그렇게 미리 detect를 하더라도 어차피 EX stage까지 그 정보를 가져가야한다. 어차피 Forwarding이 들어와야하는건 EX stage의 초반부이기때문이다. 그래서 rs1, rs2를 ID/EX까지 끌고와서 저장해주는 것이다.(마지막 회로에 표현돼있음.)
rd는 원래 마지막까지 같이 가는 정보니까 따로 더 저장하진않고..
2. 그런데 위 조건만 봐선 오류가 있을 수 있다. 전혀 다른 instructions인데 우연히 위 조건을 만족할 수 있기 때문이다.
회로는 그냥 기계적으로 값을 가져와서 읽을 뿐이니 조심해야한다.
이를 방지하기 위해서 우리는 각 경우에 대해
type1: EX/MEM.RegWrite = 1
type2: MEM/WB.RegWrite = 1
을 확인해봐야한다.
앞쪽에 들어온 inst의 RegWrite가 켜져있단 말은 뒷쪽 rs에 영향을 미친다는 말이다.(1번은 만족할때보는거니까)
(지금 우리가 보는 경우에선 저게 1로 켜져있으면 R-type inst.이거나 load inst. 둘 중 하나다.)
3. 마지막으로 하나 더 확인해야할게 있는데, 앞쪽 instruction rd위치에 x0이 아니란걸 봐야한다.
x0에 값을 쓰면 그 값은 날라가기때문에, forwarding을 하면 오히려 이상한 값이 나온다. 그냥 0을가져가서 쓰게하면된다.
type1: EX/MEM.RegisterRd != 0
type2: MEM/WB.RegisterRd != 0
Forwarding Unit
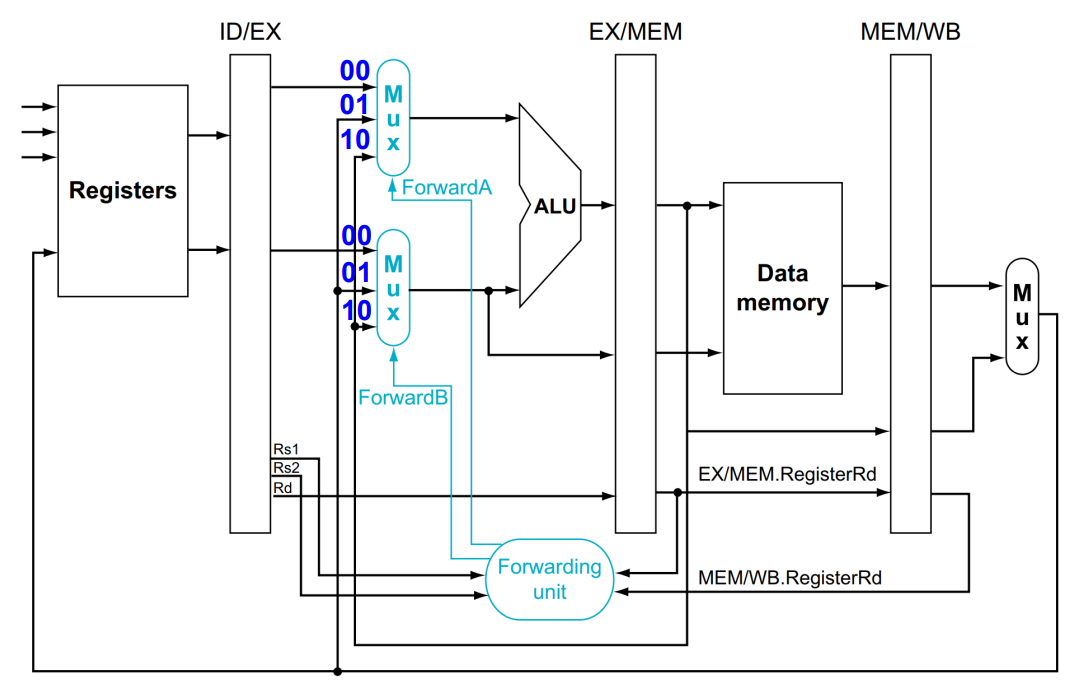
위 개념들을 이해했다면 크게 특별한건 없다.
여기서 Rs1과 Rs2가 뜬금없이 ID/EX에서 나오는데, 마지막에 나오는 회로를 보면 IF/ID에서 저 정보들을 저장해주는 것을 알 수 있다.
또 RegWrite 신호도 두개 필요한데 연결이 안돼있다, 그것도 마지막 회로도에 보면 잘 연결 돼있다.(얘는 좀 부실한듯)
EX stage의 ALU로 들어가기전 Forward 결과에 따라 올바른 값이 ALU로 들어간다.
Forwading Unit은 Data Hazard 탐지 결과에 따라 각 MUX에 다음과 같은 신호를 보낸다.
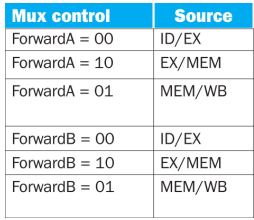
각 logic을 seudo code로 보면 다음과 같다.
//EX Hazard(type1) 판단,처리
if (EX/MEM.RegWrite and (EX/MEM.RegisterRd ≠ 0)
and (EX/MEM.RegisterRd = ID/EX.RegisterRs1)) ForwardA = 10
if (EX/MEM.RegWrite and (EX/MEM.RegisterRd ≠ 0)
and (EX/MEM.RegisterRd = ID/EX.RegisterRs2)) ForwardB = 10//MEM Hazard(type2) 판단,처리
if (not(EX/MEM.RegWrite and (EX/MEM.RegisterRd ≠ 0)
and (EX/MEM.RegisterRd = ID/EX.RegisterRs1))
and MEM/WB.RegWrite and (MEM/WB.RegisterRd != 0)
and (MEM/WB.RegisterRd = ID/EX.RegisterRs1)) ForwardA = 01
if (not(EX/MEM.RegWrite and (EX/MEM.RegisterRd ≠ 0)
and (EX/MEM.RegisterRd = ID/EX.RegisterRs2))
and MEM/WB.RegWrite and (MEM/WB.RegisterRd != 0)
and (MEM/WB.RegisterRd = ID/EX.RegisterRs2)) ForwardB = 01EX Hazard? MEM Hazard? 무슨 의미지?
: 책에서도 여기서 딱 한번 나오는 용어던데 그냥 EX/MEM pipeline reg와 발생한 hazard, MEM/WB pipeline reg와 발생한 hazard에서 앞글자들을 따왔다고 생각해도 무방할듯
MEM Hazard는 조건이 더 필요하다. 특정 inst가 앞에 두놈 모두에 dependency가 있다고 해보자.
조건문 따라서 아무거나 받아오는게 아니라 최근 값인 EX/MEM의 값을 forwarding 해와야 할 것이다.
따라서 특정 instruction이 바로 앞의 놈에게 dependency가 없을때"만" MEM/WB에서 값을 가져오도록 해야한다.
그러므로 조건 앞에 "and not"을 추가해서 EX/MEM에 진행중인 inst와 dependency 없을때만 이게 작동하도록 한다.
rs1을 기준으로 dependency가 있는지 볼거라면, rs1으로 바로 앞의 inst와 앞앞의 inst 둘 다에 대해 dependency를 확인해보면 된다.
Load-use Hazard
Load-use Hazard도 Data Hazard의 한 종류이긴하다. 즉, 마찬가지로 rd에 데이터를 쓰고있는데 뒤 inst에서 그 register를 사용하려는게 문제인거다.
일반 Data Hazard와 다른 점은 앞 instruction에서 rd에 data를 쓰는데 그게 load instruction이란 것이다.
앞서 Data Hazard Detection과 Forwarding Unit으로 우린 Data Hazard를 없애고, 그 penaly도 없앴다.
하지만 load-use는 위 방식대로 회로를 변경해도 해결되지 않는다. 왜냐하면 load가 앞에 와있으면 rd에 적힐 데이터는 MEM stage가 끝나야 나오기 때문이다. 일반 data hazard라면 바로 뒤에 dependency가 있는 inst가 따라오더라도 forwarding 해줄 결과가 EX만 지나면 바로 나오기때문에 가능했지만, load-use처럼 MEM stage 이후에 forwarding 해줄 결과가 나온다면 바로 뒤의 inst의 EX 단계에서는 원하는 결과를 토스해줄수가 없다.(이해 안되면 그림보며 잘 생각해보기)
따라서 위에서 짠 회로를 load-use hazard인 경우에도 적용시키려면 한 cycle을 stall 해야한다. 한 cycle을 stall 해주기만하면 일반적인 Data Hazard의 type2처럼 바뀌므로 위의 회로로 처리할 수 있게 된다.
따라서 우리는 Load-use Hazard인지 탐지해서 load instruction 뒤에 bubble 하나를 넣어주는 과정이 필요하다.
버블을 하나 넣어주기만하면, 나머지 과정은 위에서 짠 회로가 처리해준다. 위에 회로 보면 hazard detection할때 load도 같이 탐지된다.
(근데 보통 컴파일러 같은데서 code reordering 되기때문에 버블 넣을 일이 많을진 모르겠음)
그걸 해주는 unit인 Hazard Detection Unit을 알아보자.
logic은 아래와 같다. load instruction이라면 MemRead 신호가 1인 것을 이용해 판단한다.
이 경우에서 x0 여부를 확인하지 않는 이유는 아마 컴파일러에서 애초에 ld의 rd에 x0가 오는 형식을 지원을 안하도록해서 그런게 아닐까 생각해본다.(한번 해보니 그렇네)
if ((ID/EX.MemRead = 1)
and ((ID/EX.RegisterRd = IF/ID.RegisterRs1)
or (ID/EX.RegisterRd = IF/ID.RegisterRs2)))
stall the pipeline
//type2인 load-use hazard는 여기서 처리할 필요X. forwarding logic에서 잘 처리됨얘는 일반 Data hazard detection과 ID 단계에서 load-use인지 확인한다.(당연히 뒤 따라 들어오는 inst 기준으로 ID)
빠르게 확인해버리고 bubble을 넣어버려야 손해가 적다.
이렇게 load-use임을 detect 하고나면 bubble을 넣어줘야한다.
바로 뒤따라 들어와있는 inst를 지우고, 지운 자리 뒤에 다시 그 inst를 넣어주는 방식으로 그 사이에 bubble을 만든다.
자세히 얘기하자면, load inst 뒤의 inst가 ID stage에 왔을때 load-use hazard이라고 판단된다면, 해당 inst는 EX stage로 넘어갈때 control 신호가 모두 지워지면서 bubble이 된다. 그리고 ID stage에는 다시 지워진 그 inst가 들어오도록 하면 bubble이 들어가는 것이다.
회로에서 보자.
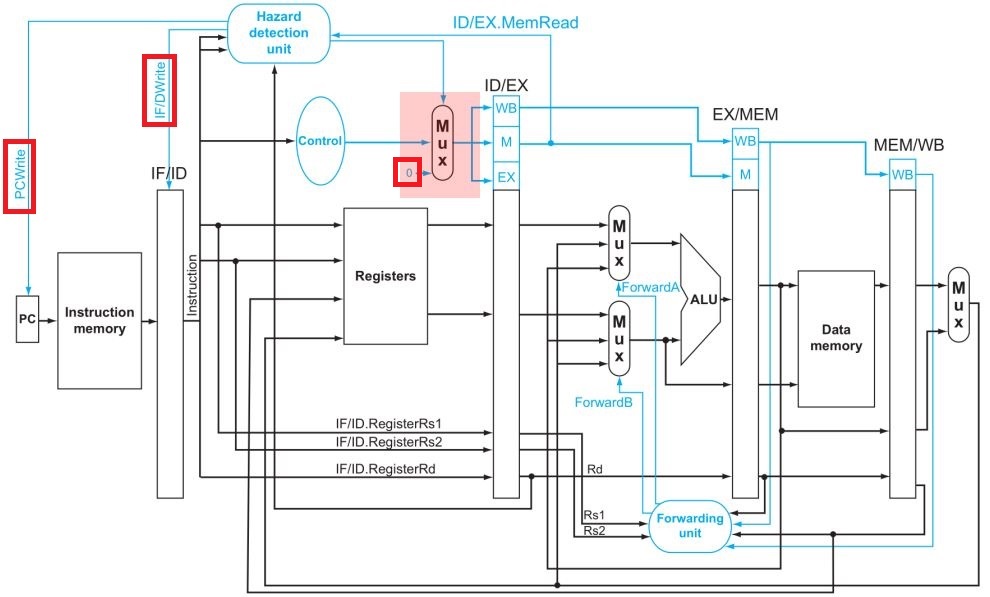
1. PC와 IF/ID에 각각 Write 회로를 연결하고, Load-Use 상황일때 write신호를 0으로 줘서 값이 못쓰이게 한다.
: 예를들어 이해해보자. IF stage부터 순서대로 add, sub, beq가 들어있다고 해보자. beq와 sub 사이에 data dependency가 존재한다. 위에서 설명한대로 sub가 EX stage로 가면서 bubble이 돼야하고, ID stage에는 그대로 sub가 남아있게 해야한다. ID stage에 sub가 남아있으려면 IF/IDWrite를 0으로 해서 아무 값도 덮어씌워지지않게한다면, EX~WB는 진행이 되지만 ID는 멈춰있을 수 있게된다. 단, 이렇게 할 것이라면 IF stage도 멈춰있도록 해야한다. 안그러면 IF stage에 있던 add는 날아가버릴 것이다. 그래서 PC의 write도 0으로 해주는 것이다. (PC write를 0으로 해뒀다가 다음 clock에 다시 1로 하면 다음엔 +4된 값이 중간에 빼먹는거 없이 잘 들어옴)
2. Control로 가는 MUX에 0이 통과되도록하여 EX로 넘어가는 inst를 bubble로 만든다.
: 사실 값을 아예 초기화하는게 안전하겠으나 책에서 그냥 이렇게 설명함.
load-use hazard인 경우 앞쪽에서 이렇게 한 cycle stall만 해주면 위에서 만들어둔 forwarding logic이 type2 hazard로 인식하고 알아서 처리한다.(다시한번 말하지만 위 포워딩 로직에서 R-type은 물론이고, load인 경우도 같이 식별되기 때문에 버블 하나만 끼워주면 처리 되는 것)
3. Control Hazards
(Control Hazard는 실제로 회로로 짜려면 너무 복잡해지기때문에 개념/문제점과 간단한 버전의 회로만 본다.)
Control Hazard를 해결하는데는 Stall을 할 수도 있고 Prediction을 할 수도 있는데, Prediction은 실패해도 Stall과 penalty가 같으므로(실패해도 본전이므로) 일단 하는게 이득이라고 했다.
Static Branch Prediction은 간단하니, Dynamic Branch Prediction에 대해 쫌 더 알아보자.
우리가 본건 stage 5개짜리라 크게 못느낄 수도 있는데, 실제는 stage가 10개가 넘어갈 수도 있다. 그런 경우에 prediction이 실패한다면 penalty가 높다. 따라서 runtime information을 사용해 성공 확률이 높은 Dynamic Prediction을 사용하는게 더 좋다.
Dynamic Prediction은 Branch prediction buffer를 사용하여 예측한다.(위에서 말로만 설명하긴했는데 다시한번 보자)
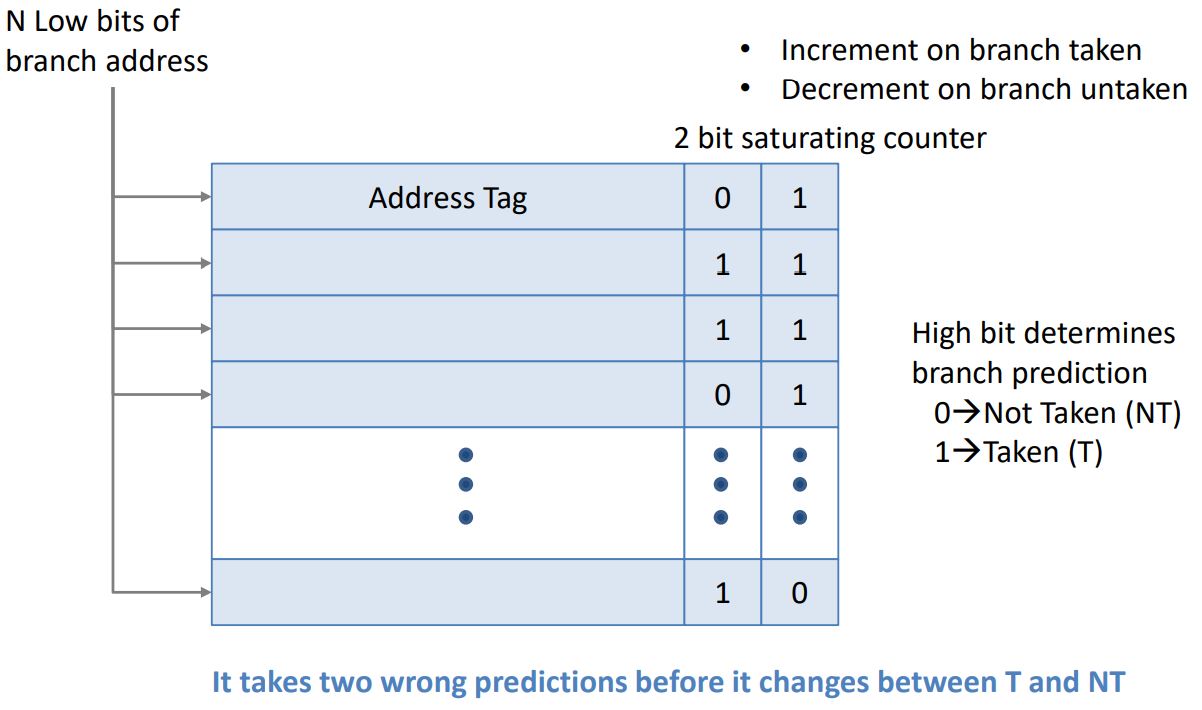
Cache랑 구조가 유사하다. Branch inst가 등장한 주소를 이용해 BHT에서 위치를 찾는다. Address Tag는 Cache에서 Tag와 같은 개념이다.
메모리에서 Text 영역의 instructions을 쭉 보다가 Branch inst가 등장했다고 해보자.
BHT에서 위치를 찾고, 기록된 값을 본다.(당연히 tag가 일치하는지도 보겠지?)
MSB가 1이라면 Branch를 하고, 0이라면 하지 않는다.
이후 실제 Branch 결과에 따라 해당 history 값을 1 증가시키거나 1 감소시킨다.
위에서도 말했듯이, 허점이나 오차가 당연히 있겠지만 이는 감수한다. CPU가 빠르게 돌아가고 있는 와중에 꼼꼼하게 할 수 없다. 또 CPU 내부에 BHT가 존재하므로 용량이 큰 BHT를 만들기도 힘들다. (BHT가 어느 정도 크기를 넘어가면 성능 향상이 그렇게 크지도 않다.)
Branch prediction buffer는 Branch History Table(BHT) 혹은 Branch History Buffer(BHB)라고도 불린다.
위 그림에 보면 history를 기록하는 곳을 2-bit "saturating" counter라고 했다. 일반적인 counter는 11일때 1이 더해지면 다시 00으로 돌아간다. 하지만 saturating counter는 11일때 1이 더해져도 11로 계속 유지되는 counter이다.
Extra HW
한단계 더 나아가보자. 회로를 변경/추가(Extra HW)해서 "Prediction이 실패했을때 penalty를 줄여보자."
아무 변경없는 회로에선 branch 결과를 알려면 MEM stage가 끝날때까지 기다려야하므로 prediction 실패시 penalty는 3 clock cycle이다.(아래 그림 참고, 빨간 부분을 다 날려야 함.)
왜냐하면 변경 없는 회로를 보면 MEM stage에서 branch 수행 여부와 타겟 instruction을 계산하기때문에 MEM이 끝나야 다음 inst가 정확히 무엇인지 알 수 있다.

업그레이드될 회로의 기본 원리는 이런 penalty를 줄이기위해 EX에서 branch판단/시행 하던 것을 ID에서 미리 해보자는 것이다. (IF에선 이제 막 fetch해오기때문에 무리가 있다.) (이렇게 미리 하게되면 EX에서 branch 관련 logic은 필요없다.)
1. Branch Decision을 좀 더 빨리 내려보자.
: EX의 ALU에서 equality test 기능만 ID에서 할 수 있도록 간단한 HW만 추가해주면 된다. 굳이 ALU를 다 가져올 필요가 없다, 애초에 그걸 쓰는 다른 inst들도 있어서 가져오지도 못한다. 간단하게 rs1과 rs2의 equality test만 하는 회로를 만들어서 register file 뒷쪽에 붙여주면 된다. 이렇게 바꾸면 기존 ALU의 zero 신호 내보내는 부분은 없어져도 OK.
(이때 빼기해서 비교할 필요도 없고 xor 해버리면 된다. 빼기는 순차적으로 해야되지만 xor같은건 각 bit별로 병렬로 처리가능해서 빼기보다 빠르다.)
2. Branch target Address도 좀 더 빨리 계산해보자.
: Branch를 하든 말든 일단 계산을 빨리해두고, 만약 branch를 해야한다고 판단되면 곧바로 branch를 할 수 있도록 한다.
branch target address를 구하는데 쓰던 Adder을 EX에서 ID로 옮겨버리면 된다.(ID의 기존 회로들과 병렬로 처리되므로 손해가 크진 않을듯)
그런데, 이렇게 HW를 변경/추가 하게되면 문제점이 있다.
1. ID까지 forwarding을 "추가로" 해줘야한다. ID의 equality test unit에 dependency가 있는 data가 필요할 수 있기때문에, EX/MEM과 MEM/WB에서 forwarding을 EX가 아닌 ID까지 해줘야한다.(기존 forwarding 회로는 EX의 ALU에서 계속 사용해야되니까 그대로 놔두고 ID로"도" forwarding되도록 "추가"해야한다.)
2. ALU inst 이후에 branch inst가 따라오고 의존성이 있는 경우(branch일때 일반 data hazard), 1번처럼 forwarding을 해주더라도 1개의 bubble이 필요하다.
3. load inst 이후에 branch inst가 따라오고 의존성이 있는 경우(branch일때 따라오는 load-use hazard), 1번처럼 forwarding을 해주더라도 2개의 bubble이 필요하다.
1번에서, 왜 EX/MEM, MEM/WB에서만 포워딩해주지? ID stage로 가는거니까 ID/EX에서도 따오면 되지않나?
: forward라는게 값이 나와야 할 수 있는거다. 그리고 그 값이 나오는 단계는 EX stage이다. 값도 안나왔는데 forwarding을 해줄 순 없다.
Control Hazard를 해결하기위해 equality unit을 ID로 끌어왔고, 그에 따라 forwarding logic도 추가가 됐다고 하자. 그럴때 branch이면서 data hazard 상황이 되면 어떻게 되는지를 본 것이 2번과 3번이다.(branch가 낑긴 경우를 본거지, 일반적인 Rtype 두개 연속 나오거나 하는 data hazard는 기존처럼 EX에서 잘 작동함. branch가 낑기면 ID에서 처리해야하기때문에 버블이 필요한 것)
(좀만 생각해보면 왜 각각 1,2개 버블이 필요한지 알 수 있음. Data hazard에서 stall할때 ID와 WB가 같은 위치에 있을 수 있었던건 reg file 내부 회로 덕분이었던거지 보통은 그냥 앞의 작업이 끝나고 다음 단계가 와야한다는거 주의)
아래는 Branch 최적화 관련 HW가 추가된 간단한 개념만 보여주는 회로이다.
(바로 위에서 말한 포워딩 문제는 딱히 표현 안돼있다. 개념만 보여주므로 엄밀하지않고 허점이 많다.)
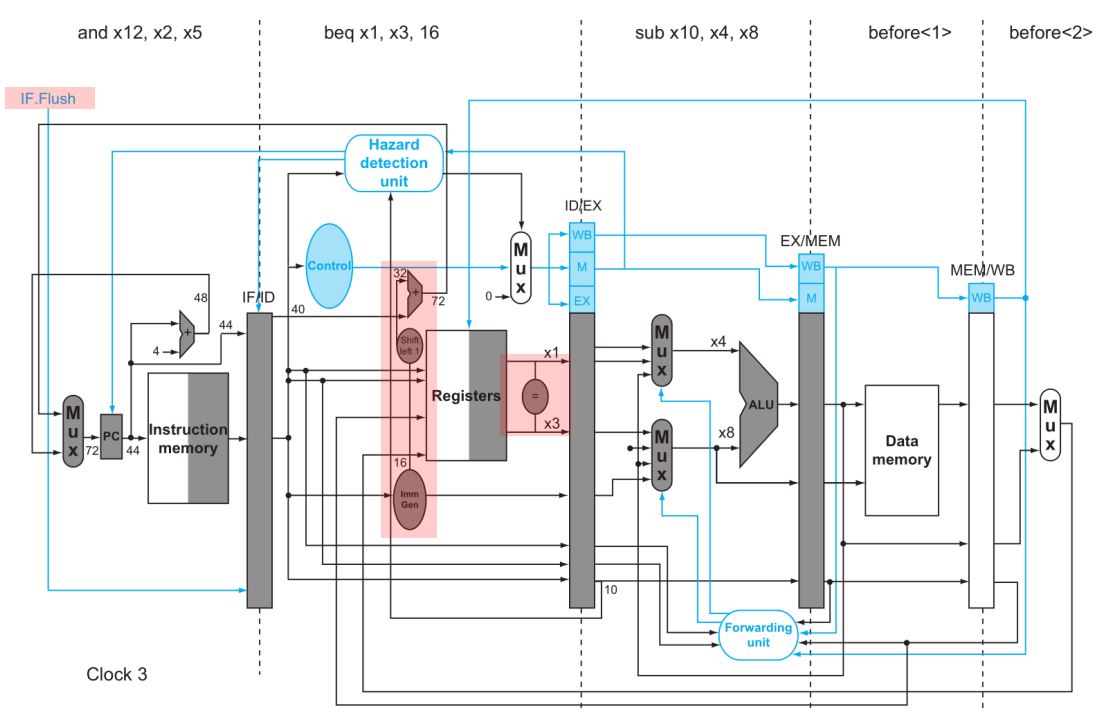
Shift1과 Adder과 ID로 왔다. 또 reg File 뒤에 간단한 equality test하는 회로가 추가됐다.
(이 equality 회로에 뒤에서 forwarding 해오는 선들이 연결돼있어야 할거임)
좌측 상단에 IF.Flush 신호도 추가됐다. 이 신호를 이용해 다음으로 IF/ID에 들어올 instruction(현재 IF stage를 진행중인 inst)을 nop으로 바꾼다. nop은 아무 액션도 취하지 않고 아무 상태변화도 시키지 않는 instruction이다.
예를들어 위 그림에서 beq다음 and가 오면 안된다고, beq의 ID stage에서 판단됐다면 IF.Flush를 1로 설정해둔다. 그럼 다음 clock이 튈때 and inst는 IF/ID로 들어오지 못하고 그대로 nop으로 날아간다.
and가 예측을 잘못한 결과로 판정된다면, 한 클락이 튀었을때 아래와 같이 된다.
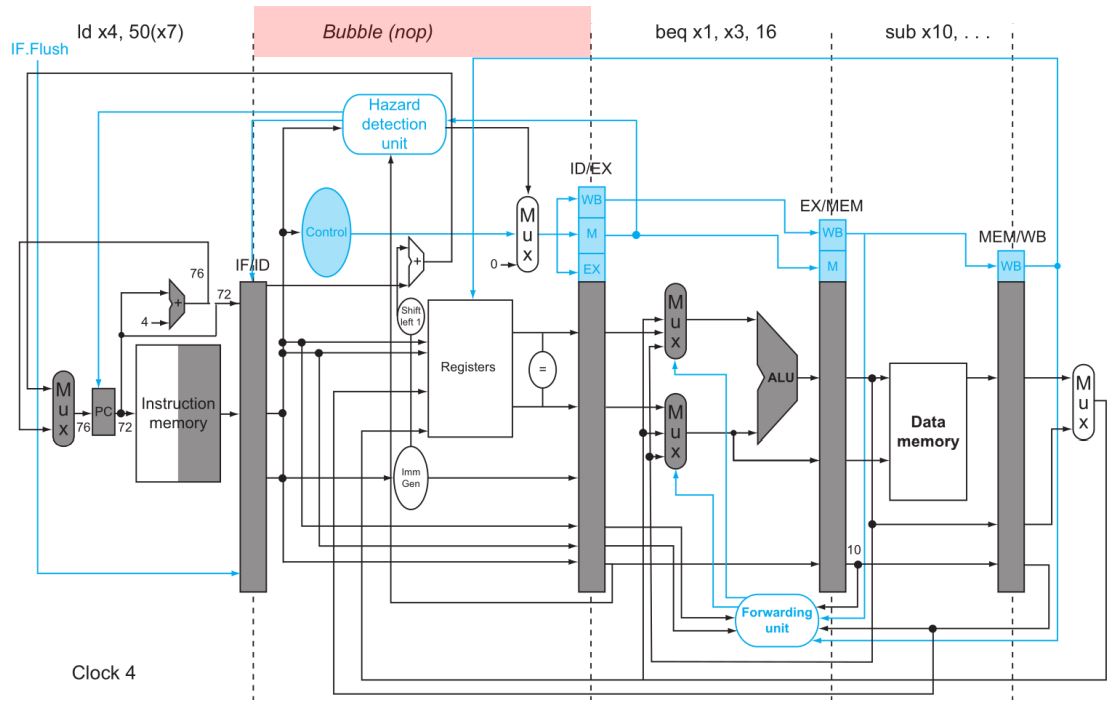
nop이 들어가고, 그 다음 제대로 된 branch 결과가 fetch된다.
원래는 prediction 실패하면 3 cycle을 버려야되지만, HW 추가로 branch 판단/계산을 빨리할 수 있게되어 penalty가 1 cycle로 줄어든 것이다.
(아마 저 버블은 reordering처럼 어떻게 해결은 안될 것 같다고 하심. 애초에 중간에 뭘 넣는다는게 쉽지 않으니)
왜 여기선 nop으로 버블을 주고 load-use hazard에선 control에 0을 줘서 bubble로 만들지? 거기서도 그냥 Flush 해버리면 안되나?
: 책에 보니 그냥 둘이 원리는 같은듯. Flush가 좀 간편하게 편한거인듯? 대신 Flush가 위 그림에선 하드웨어 최적화해서 하나만 해도 되지만, 하드웨어 최적화 안돼있으면 3개 instructions을 Flush해야겠지.
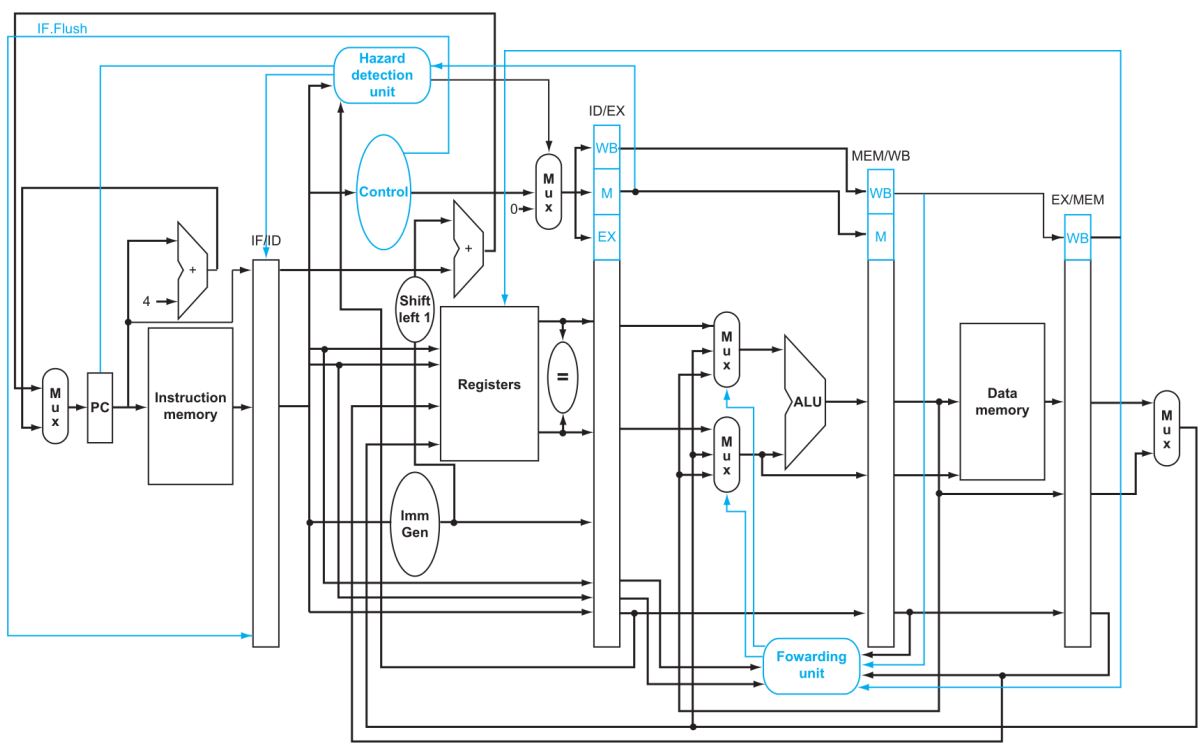
최종 Pipelined Datapath
> Data Hazard 복습 정리
아무런 forwarding 처리 없이 기초적인 단계에서부터 보자면,
Data Hazard (Load-Use 아닌 경우)
type1 : bubble 2개 필요
type2 : bubble 1개 필요
Load-Use Hazard
type1 : bubble 2개 필요
type2 : bubble 1개 필요
즉, 아무 HW 변경이 없다면 Load-Use 이든 말든 Data hazard면 "전부 다" 앞에 나온 instruction이 WB까지 갈 수 있도록 기다려야한다.(이전 inst의 WB와 뒤 inst의 ID가 동일 선상에 있도록 맞춰줄 수 있을때까지 기다려야함. 즉, 둘 사이 간극이 2칸 돼야함.)
forwarding이 회로가 추가되면 좀 다르게 생각해야한다.(forwarding이 있는거하고 없는거는 근본 원리부터 다르다. 엮으려 하지말고 각각 이해하자.)
forward 기능이 있으면,
Load-Use가 아닌 일반 Data Hazard는 type1/2 모두 아무 bubble 없이 해결할 수 있다. type1/2 둘다 해결하는 회로가 있다면 말이다.
하지만 Load-Use는 forwarding이 있어도 좀 생각해봐야한다. load type은 "필요한 데이터가 무조건 MEM stage 이후에" 나온다. 일반 R-type이면 필요한 데이터가 EX stage 이후에 나온다는 점과 다르다.
그렇기때문에 Load-use hazard여도 type2라면 잘 해결이 된다.
하지만 type1이라면 무조건 bubble 하나가 필요하다. 왜냐하면 필요한 데이터는 MEM 이후가 돼야 나오기 때문이다. EX이후에 연결된 forwarding unit은 쓸모가 없어지므로 type2로 만들어주는 것이다.
근데 보통은 code reordering으로 load-use hazard로 감지 안되고 바로 type2로 그냥 감지되도록 컴파일러에서 순서를 잘 바꿔 줄 것이다.
이렇게 forwarding 회로를 추가하긴하는데, "꼭 load-use가 아니더라도 dependency만 있으면" 일단 compiler 같은데서 1차적으로 code reordering을 해주고 최대한 자연스럽게 진행되게 해주고 나서 forwarding 로직에 넣을듯.
ㅡㅡㅡ
Forwarding이랑 branch일때 Extra HW 전부 다 추가됐다고 했을때 모든 경우에 대해 버블이 몇개씩 필요한지 보자.
1. 일반적인 Data Hazard(no load-use, no branch) : No bubble
2. load-use Hazard(no branch) : 1-bubble
3. 일반적인 Data Hazard인데, 뒤에 따라오는 inst.가 branch문인 경우 : 1-bubble
4. load-use Hazard인데, 뒤에 따라오는 inst.가 branch인 경우 : 2-bubble
'수업 > Computer Architecture' 카테고리의 다른 글
| [Computer Architecture] Processor - 1 (0) | 2022.11.08 |
|---|---|
| [Computer Architecture] Memory Hierarchy (0) | 2022.10.20 |
| [Computer Architecture] Arithmetic for Computers(2) (2) | 2022.10.18 |
| [Computer Architecture] Arithmetic for Computers(1) (0) | 2022.10.13 |
| Language of the Computer (5) | 2022.09.14 |