Physical Architecture Layer Design도 requirements가 가장 기본이다. 특히 non funcitonal Requirements를 기초로 디자인한다.
우선 Physical Architecture Layer Design의 기본 요소들을 알아보고, 글의 마지막쯤에 어떤 requirements일때 어떻게 설계하는게 좋은지 알아본다.
대부분의 현대 System들은 한 컴퓨터에만 존재하는게 아니라 network를 통해 여러 computers에 분산돼있다.
(그냥 한 컴퓨터 안에서만 돌아가는 standalone system은 요즘 찾기 어렵다.)
Physical Architecture Layer는 다음을 명시하는 layer이다.
1. 이전 단계들에서 만든 System의 SW 부분을 computer들에 어떻게 분배시킬지
2. 어떤 HW와 SW를 사용할지
"physical architecture layer을 설계하는 목적은 애플리케이션 소프트웨어의 어떤 부분이 어떤 하드웨어에 할당될 것인지를 결정하는 것이다."
(이 작업은 쉽지 않으므로 보통 전문 컨설턴트를 고용하거나 매우 경험 많은 분석가를 작업에 할당한다.)
Architectural Components
1. SW componenets
- Data storage : DM Layer의 object persistence와 연관됨
- Data access logic : DM Layer의 data access와 manipulaction을 하는 classes와 연관됨
- Application logic : PD Layer에 해당
- Presentation logic : HCI Layer에 해당
2. HW components
- Clients
- Servers
- Networks
위 SW 구성 요소들을 HW 구성요소에 어떻게 배치시킬지가 관건이다. 이전까지 SW를 만드는 것에 집중했다면 이제 우리가 만든 SW를 HW와 어떻게 접목시킬지 보는 것이다.
배치할 수 있는 방법이야 매우 다양하겠지만, (1)Server-Based, (2)Client-Based, (3)Client-Server 세가지 architecture 모델 중 하나를 주로 사용한다.
(오해하면 안되는게, SW를 어떻게 분배하냐에 따라 아키텍쳐 종류가 나뉘는 것이다. HW에 따라 어느 정도 제약은 있겠지만, 우리 컴퓨터에 따라 아키텍쳐 종류가 나뉘는게 아니고 컴퓨터 내의 SW가 어떻게 배치돼있냐에 따라 그 SW가 사용하는 아키텍쳐 종류가 나뉘는 것이다.)
1. Server-Based Architectures
Server에 4가지 application functions을 모두 할당해두는 것이다.
client는 I/O를 해주는 간단한 기계에 불과하다.
초기 System들이 이 방식의 아키텍쳐를 많이 사용했다. 이런 I/O 수준의 동작만 제공해주는 client를 terminal이라고 한다.
Server내의 SW가 발전하면 발전할수록 Data가 많아지면 많아질수록 server가 처리할 양이 많아져 overload 걸리기 쉽다.

2. Client-Based Architectures
Data Storage를 제외한 모든 로직을 Clients에 할당해두는 것이다. Server는 그저 데이터를 담는 공간에 불과하다.
이때의 Clients는 지금 우리가 사용하는 personal computers이다.
이 아키텍쳐는 개발은 쉬우나 많은 traffic으로 server에 loverload가 걸리기 쉽다는 것이 단점이다.
(아래 그림에는 client가 하나 뿐이지만 사실은 여러개가 Server에 연결돼있음)
이 방식의 System은 예시 ~~?
3. Client-Server Architectures
한쪽에 거의 몰아서 배치하는 위 두 아키텍쳐와 달리 Client와 Sever에 밸런스를 맞춰서 SW를 배치하는 방식이다.
현대 System에선 거의 이 방식만 쓴다.
Application Logic을 어디 배치하냐에 따라 Thin Client와 Thick Client로 나뉜다.
Thick Client로 설계한다면, Server로 가는 data traffic이 줄어든다.
Client-Server 방식의 장점은 Highly Scalable(확장성↑)하단 것이고, 단점은 구현하기 복잡하다는 것이다.
Client-Server Architecture는 Tiers에 따라 나뉘기도 한다. 바로 위 그림이 2-tier이다.
아래 그림은 3-tier 이다. 한 Server를 Data Server로 하여 Data관련 로직 두개를 넣어두고,
중간 서버에서 App logic을 담당하도록 한다. Client는 Presentation Logic만 갖는다.
4이상의 tier를 가지도록 할 수도 있는데, 그렇게 하려면 App logic을 더 쪼개서 중간 서버에 분배하면 된다. 끝단의 Client가 Presentation logic을 가지고, 반대편 끝의 Server가 Database server로서 Data access logic과 Data storage를 갖는다는 점은 tier가 늘어나도 변하지 않는다.
각 Architecture별 특성은 아래 표에 정리돼있다.
개발 비용은 Client-Server가 제일 높다. 이게 가장 구현하기 복잡하다고 한다.
Server-based가 개발이 더 어렵다. 왜냐하면 Server-based system은 주로 우리에게 친숙하지 않고 전문화된 기술을 필요로 하기 때문이다. 반면에 Client-based나 Client-Server는 우리에게 친숙한 GUI 기반 개발 도구를 이용할 수 있어서 오히려 이게 더 쉽다.
(Cost of development는 좀 더 다양한 측면에서 본 것이고, Ease of development는 그냥 딱 개발/구현할때의 친숙성/기술 정도만 보고 말한거인듯)
Security를 관리하기에는 Server-based가 제일 좋다. Server에서만 보안을 잘 점검해주면 되기 때문이다. 그래서 원자력 발전소 같은데 컴퓨터는 주로 Server-based이다.
Examples
- The World Wide Web(WWW) : Client-Server
- Email : Client-Server
- Network File System : Client-based
- Transaction Processing System :
- Remote Display System : Server-based
- Communication System :
- Database System :
~~?
Infrastructure Design
실제로 어떤 특정 Computers에 어떤 SW를 설치할지를 디자인하는 것이다.
대부분 디자인은 이미 존재하는 시스템을 활용하므로 잘 파악해야 한다.
두 종류의 방식으로 Infrastructure Design을 표현한다.
1. Deployment diagram
2. Network model
Deployment Diagram
HW와 SW사이 관계를 표현한다. 세가지 구성요소로 이루어져있다.
- Nodes : HW를 표현
- Artifacts : node에 설치될 information system의 일부분을 표현
- Communication paths : nodes간 communication link를 표현
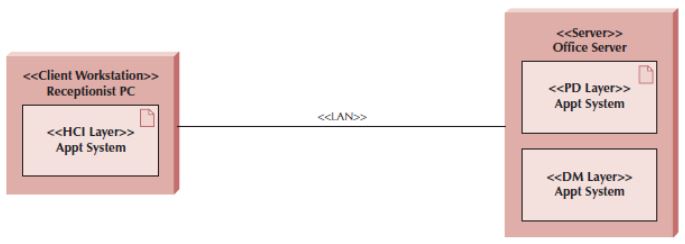
deployment diagram의 예시이다. Receptionist PC나 Office Server가 node이고, 그 안에 있는 박스들이 Artifacts이다.
두 node는 LAN이라는 communication path로 연결돼있다.
아래처럼 그림으로 표현할 수도 있다.
아래 그림은 HW 설치/구성하는 사람에게 필요한 그림이고, 위 그림은 SW를 설치하는 사람에게 필요한 그림이다.

Hardware&Software Specification
HW&SW Specification이란 application을 지원하기 위해 어떤 HW와 SW가 필요한지 기술하는 문서이다.
SW requirements에는 OS나 특정 SW가 명시될 수 있고, 훈련이 필요한지, 유지보수, 보증, license까지 모두 확인해야한다.
HW requirements에는 정확히 어떤 HW를 사용할지 명시해야한다. 최소 spec 같은 것도 명시해야한다.
(requirement에 없더라도 찾아내서 명시해야한다.)
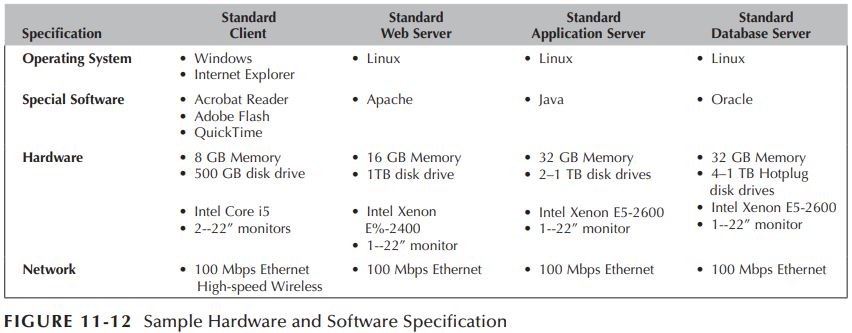
Requirements에 따른 Architecture 선택
Physical Architecture Layer도 Nonfunctional Requirements와 밀접하게 연관돼있다. Nonfunctional requirements로부터 Architectural design을 해나가야한다. (requirements는 모든 설계 단계의 기초인듯)
각종 requirements를 파악하여 가장 적합한 Architecture을 정해야한다.
어떤 requirements일때 어떤 Architecture를 고르는 것이 좋은지
자세한 예시는 강의자료 ppt ch11 p.20부터...
(옮기려했는데 양도 많고 딱히 정리하기도 그래서 그냥 강의자료 보는걸로)
Appendix : Client-Server Framework
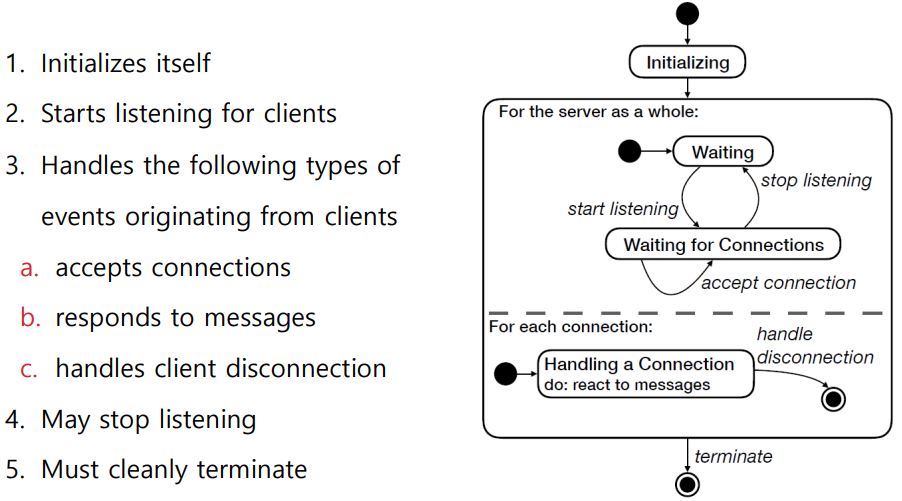
Server의 동작을 일반화 시키면 위와 같다.
서버 process 내부에선 주로 multi threading을 이용해 다중 client를 처리하도록 한다.
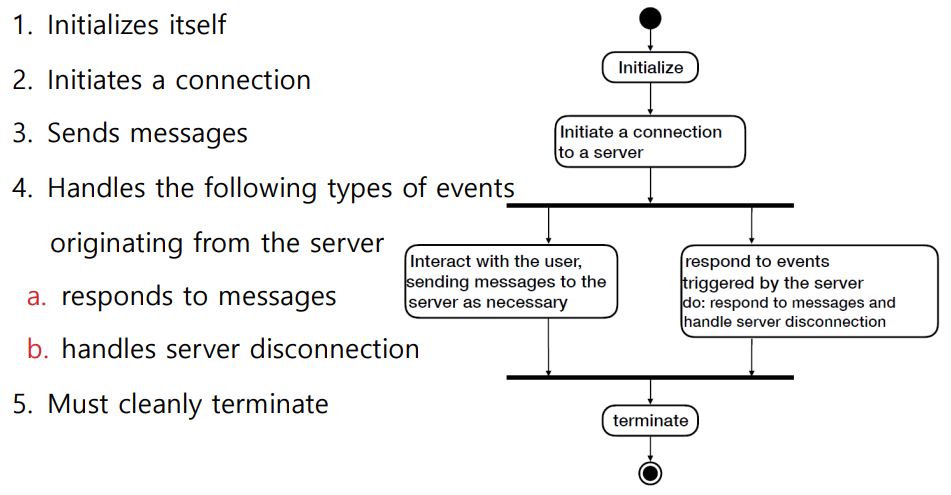
Client의 동작을 일반화 시키면 위와 같다.
두 경우 모두 아키텍쳐 레벨에서 설계된 것이고, 구체적으로 어떻게 일을 처리할지는 PD Layer에 있는 것이다.(layer별로 독립적으로 design)
즉, 이메일이든 채팅이든 client-server architecture을 사용한다면 전부 위처럼 작동한다는 것이다.
Client-Server Architecture의 기본 구조는 위처럼 모두 같으니,
보통 공통 부분은 미리 coding해둬서 Framework로 만들어 둔다. 저런 모델을 스스로 구현하기가 쉽지는 않다.
Framework란 기본적인 공통 부분을 미리 구현해둔 code와 구현안된 code(ex.PD Layer)가 합쳐져있는 것을 말한다.
즉, 공통 부분을 매번 다시 구현하지 않아도 이 Framework라는 것을 이용해 개발할 수 있다.
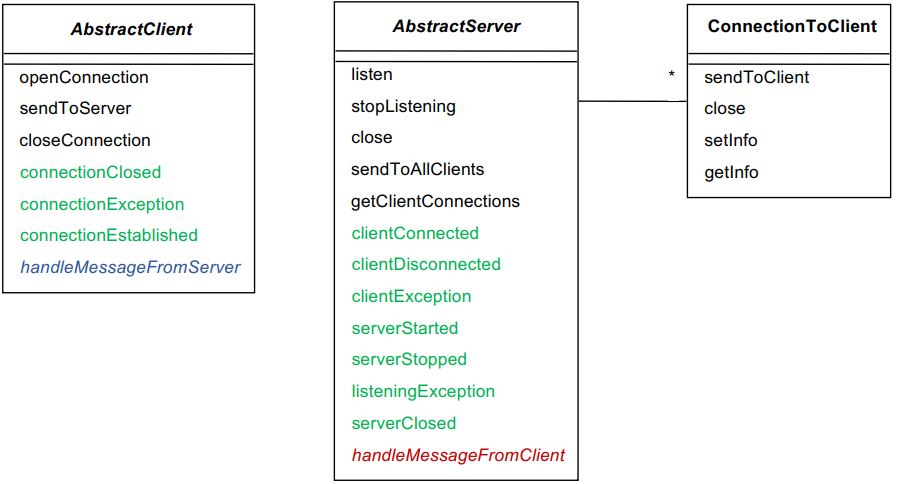
아래 그림은 Object Client Server Framework(OCSF)라는 Framework를 간단하게 보여준다.
검은 글씨가 이미 구현된 것들이고, 초록색이 override 가능한 method들, 파란색 빨간색은 우리가 알아서 구현해야하는 처리 logic이다.
AbstractServer와 AbstractClient를 상속받아서 나만의 SW을 만들 수 있다.
아래는 Client-Server app을 만들기 위해 수행되는 과정이다. 3번과정을 해둔게 아마 network protocol 같은거인듯.
이미 잘 개발돼있는게 있다면 검증된걸 가져다 쓰는게 제일 좋다. 물론 공부하는 입장에선 구현해보거나 코드 보는것도 좋긴하다고 교수님께서 말씀하셨음.

Cloud와 client-server의 차이점은 뭘까?
Cloud를 사용할때는 우리가 정확히 어떤 서버에 접근하는지 몰라도 된다는 것이 차이이다. Client-server architecture에선 우리가 어떤 server에 접근할지 IP address를 알아야하지만 Cloud에선 그럴 필요가 없다.
말고도 기존 client-server는 특정 역할을 하는 server에 client가 충분히 인지하고 접근하는 방식이었지만, cloud 시스템에선 cloud 내부에 어떤 일이 일어나는지 client 입장에서 정확히 모른다.
클라우드 컴퓨팅 여기 정리 잘 된듯 (정확하게 설명돼있는건진 모르겠으나..)
'수업 > Software Design' 카테고리의 다른 글
| [Software Design] Human-Computer Interaction Design (0) | 2022.12.12 |
|---|---|
| [Software Design] Class and Method Design (0) | 2022.12.12 |
| [Software Design] Moving to Design (0) | 2022.11.12 |
| [Software Design] Behavioral Modeling (0) | 2022.10.19 |
| [Software Design] Structural Modeling (0) | 2022.09.27 |