> TCP API 호출 순서

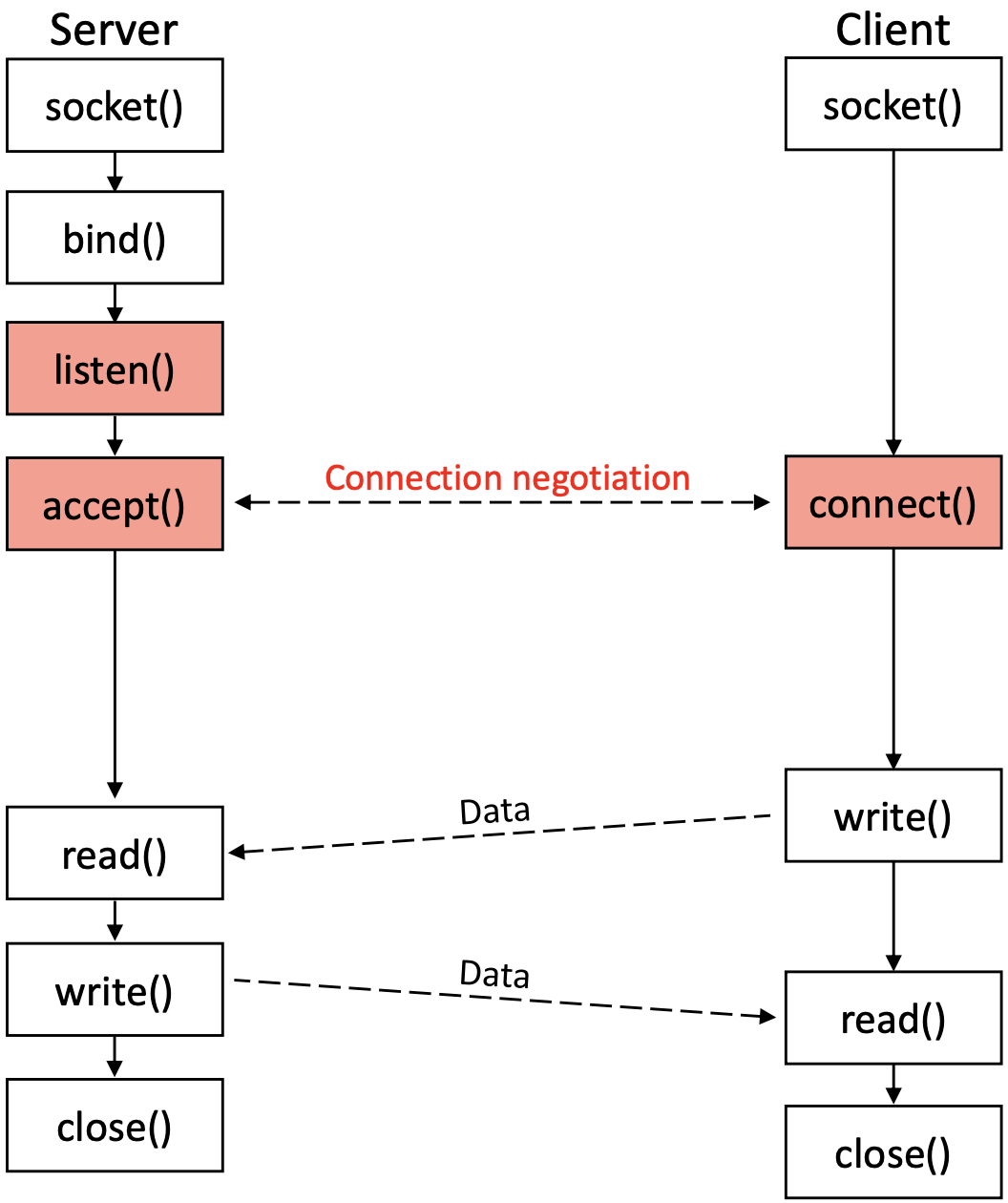
TCP Server
1. socket
#include <sys/socket.h>
int socket(int domain, int type, int protocol);우선 socket을 생성하기 위해선 socket 함수를 사용해야한다.
첫번째 인자로는 만들 socket이 사용할 Protocol Family(프로토콜 체계) 정보를 전달하고,
두번째 인자로는 소켓의 데이터 전송 방식에 대한 정보를 전달한다.
마지막 인자로는 통신에 사용할 프로토콜을 전달한다.
세 인자 모두 프로토콜과 관련있다, 즉 생성할 socket이 어떤 프로토콜을 써서 통신할지를 인자로 줘서 socket을 만드는 것이다.
성공 시 생성된 socket의 file descriptor, 실패 시 -1 을 반환한다.
> Protocol Family(Address Family) 란?
프로토콜의 종류에 따라 분류할 수 있는데, 이를 Protocol Family(Address Family)라고 한다.
socket 함수의 첫번째 argument로 protocol family(address family)를 줘야하며, 여기에 어떤 분류를 주냐에 따라 두번째와 세번째 인자로 올 수 있는 애들이 제한된다.
우린 IPv4인 "PF_INET"를 주로 사용한다. 다른 애들도 있긴한데, 얘넨 중요도가 떨어지거나 보편화가 덜 되었다.

> Socket Type
두번째 인자인 socket type에선 데이터 전송 방식을 기술한다.
PF_INET의 대표적인 socket type은 아래 두가지가 있다.
1. SOCK_STREAM
: TCP 소켓으로, 연결지향형 소켓이라고도 한다.
: 중간에 데이터가 소멸되지 않는다.
: 전송 순서대로 데이터가 수신된다.
: 데이터의 경계가 존재하지 않는다.
: socket과 socket이 1:1로 연결된다.
2. SOCK_DGRAM
: UDP 소켓으로, 비연결지향형 소켓이라고도 한다.
: 데이터 손실 및 파손 가능성이 있다.
: 전송 순서에 상관없이 빠른 속도를 지향한다.
: 데이터의 경계가 존재한다.
: 한번에 전송할 수 있는 데이터 크기가 제한된다.
Q. "데이터의 경계가 존재한다"는게 무슨 말일까?
A. 예를들어 TCP를 사용하면 데이터의 경계가 없기때문에 3번의 write를 호출해서 데이터를 송신하더라도, 1번의 read로 해당 데이터를 한번에 수신할 수도 있다. 하지만 UDP를 사용해서 데이터를 송신하면 각 데이터들은 하나의 묶음처럼 보내진다. 따라서 UDP에서 송신 함수를 3번 호출해 데이터를 보낸다면, 수신하는 쪽에서도 수신 함수를 3번 호출해야한다 한번에 그걸 다 받을 순 없다.
※참고※
TCP에선 버퍼 상태를 보며 데이터를 송신하므로 버퍼가 꽉차서 데이터가 손실될 위험도 거의 없다.(TCP에선!)
> 3번째 argument
3번째 argument로 어떤 protocol을 사용할지 명시해준다.
보통은 첫번째와 두번째 argument만 잘 적어주고 여긴 0으로 적어도 소켓을 잘 생성해준다.
하지만, 한 protocol family에서 데이터 전송 방식이 동일한 두 가지 protocol이 나올까봐 처음 socket 함수를 만들때 이 argument를 추가한 것이다.
TCP 소켓을 만들 땐 IPPROTO_TCP를, UDP 소켓을 만들 땐 IPPROTO_UDP를 argument로 작성하면 된다.
2. bind
#include <sys/socket.h>
int bind(int sockfd, struct sockaddr * myaddr, socklen_t addrlen);socket 함수를 통해 생성한 socket에 주소 정보(IP와 PORT 정보)를 할당하기위해 사용하는 함수이다. 이렇게 특정 socket을 특정 IP address와 PORT 번호로 bind 해두면, 그 socket은 해당 IP address와 port 번호로 들어오는 데이터를 수신할 수 있게 된다.
첫번째 인자로 bind할 socket의 file descriptor을 전달한다.
두번째 인자로 할당할 주소 정보를 지니는 structure 변수의 주소를 전달한다.
세번째 인자로 두번째 인자의 길이(크기)를 전달한다.
성공 시 0, 실패 시 -1 을 반환한다.
Q. 왜 내가 기술한 특정 IP 주소로 bind하는걸까? 어차피 그 컴퓨터의 IP 주소는 정해져 있는게 아닌가?
A. 맞다. 그래서 bind한 IP 주소와 해당 프로그램이 실행되는 host의 IP 주소가 다르다면 데이터 수신 자체가 안된다. INADDR_ANY를 통해 자동으로 host의 IP 주소를 사용하도록 할 수도 있지만, 왜 이렇게 따로 IP 주소를 명시할 수 있도록 해주는 걸까?
이는 한 host가 여러 IP 주소를 가지는 경우나 서버에서 특정 범위의 IP 주소에서만 연결을 허용하도록 하는 경우 등을 처리하기 위해서이다.
struct sockaddr_in & struct in_addr
struct sockaddr_in
{
sa_family_t sin_family;
uint16_t sin_port;
struct in_addr sin_addr;
char sin_zero[8];
};
struct in_addr
{
in_addr_t s_addr; //in_addr_t는 uint32_t로 정의돼있다.
};
> 구조체 멤버 설명
sin_family : Address family 정보 저장
sin_port : 16 비트의 PORT 번호 저장
sin_addr : 32 비트의 IP 주소 저장 ← 즉, IPv4 주소를 저장하기 위한 구조체이다.
sin_zero : 특별한 의미는 없으나 반드시 0으로 채워야 한다.

> IP 주소와 PORT에 대한 간단한 설명
IP 주소는 컴퓨터를 구분하기위해, PORT는 소켓을 구분하기 위해 사용한다.
한 프로그램이 여러 소켓을 가질 수도 있으므로 한 프로그램에 PORT가 여러 개 할당될 수도 있다.
> sin_zero는 왜 필요한가?
sockaddr_in 구조체의 크기를 sockaddr 구조체의 크기와 같게 맞추기 위해 필요하다. 이를 반드시 0으로 채워야하는 이유라던가 추가 적인 내용은 아래에서 설명한다.
이 구조체에 정보를 어떻게 넣는지 아래에서 자세히 알아본다.
> Byte Ordering
메모리에 데이터를 저장하는 방식은 CPU에 따라 다르다. Big endian과 Little endian이라는 두가지 방식을 사용한다.
Big Endian : 상위 byte의 값을 작은 번지수에 저장
Little Endian : 상위 byte의 값을 큰 번지수에 저장
(bit-ordering이 아니라 byte-ordering이다.)
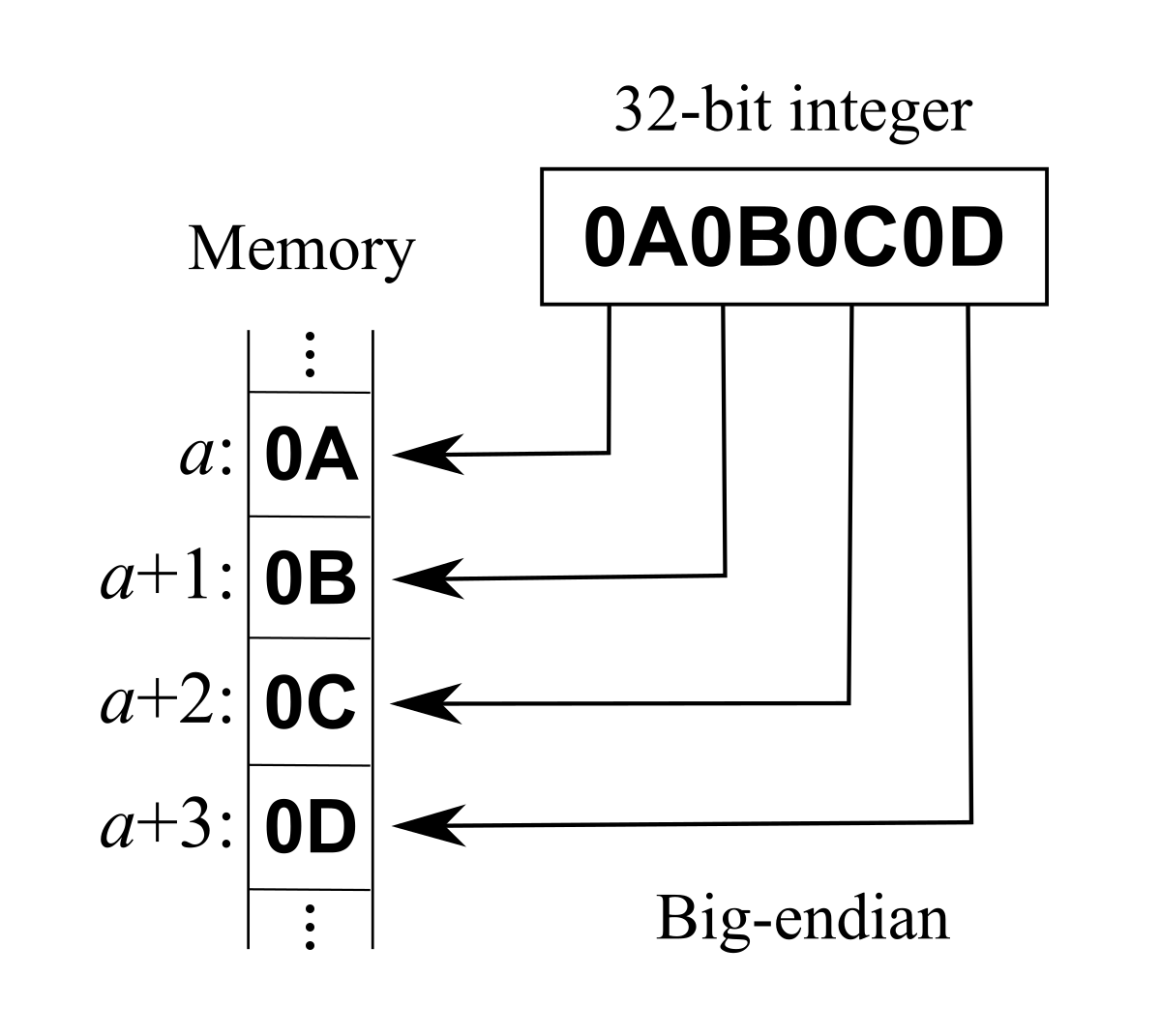
Network에선 Big-Endian을 기준으로 한다.
즉, host의 byte-ordering 방식이 어떤지 잘 보고 network로 통신할 땐 big-endian으로 내보내야 한다는 것이다.
이때 사용할 수 있는 함수들은 아래와 같다.
unsigned short htons(unsigned short);
unsigned short ntohs(unsigned short);
unsigned long htonl(unsigned long);
unsigned long ntohl(unsigned long);h는 host, n은 network를 의미한다.
s는 short, l은 long을 의미한다.
unsigned short는 16비트로 주로 MAC 주소를 표현할 때 사용되고, unsigned long은 32비트로 주로 IP 주소를 표현할 때 사용된다.
위 함수들은 host의 byte-ordering 방식에 따라 network의 통일된 byte-ordering 방식인 Big-endian 방식으로 변환해주는 함수이다.
따라서 만약 host가 Big-endian 방식을 사용한다면, 위 함수의 입력과 출력은 차이가 없다.
그럼에도 위 함수를 사용하는 것이 안전하고, 권고된다.(그 프로그램을 매번 같은 host에서만 돌릴건 아니니까..)
> 문자열 ↔ struct in_addr
#include <arpa/inet.h>
in_addr_t inet_addr(const char * string);
int inet_aton(const char * string, struct in_addr * addr);
char * inet_ntoa(strut in_addr adr);inet_addr
211.214.107.99 같이 점이 찍힌 10진수로 표현된 문자열을 전달하면, 이를 IP 주소 정보 형태의 in_addr_t type(32비트)으로 반환해준다. 실패 시 INADDR_NONE을 반환한다.
예를들어 256.x.x.x 를 전달하면, 각 바이트는 최대 255까지라 256은 불가능한 숫자라서 INADDR_NONE을 반환한다.
inet_aton
inet_addr 함수와 같은 기능을 한다. inet_addr은 반환값으로 바로 in_addr_t를 받아오지만, inet_aton은 인자로 struct in_addr 안에 그 값을 받아온다는 차이뿐이다. 성공 시 1, 실패 시 0을 반환한다.
inet_ntoa
inet_aton의 반대 기능을 한다. struct in_addr type의 데이터를 받아서 우리가 보기편한 문자열 형태로 변환한다.
성공 시 변환된 문자열의 주소 값, 실패 시 -1을 반환한다. (얘는 또 반환해주네..)
> bind() 호출 예시
이제 위에서 배운 것들을 종합해 bind()를 이용해 socket과 주소 정보(IP/PORT)를 bind 해보자.
//server socket 생성
int serv_sock;
serv_sock = socket(PF_INET, SOCK_STREAM, 0);
//bind를 위한 serv_addr 구조체 채우기
struct sockaddr_in serv_addr;
char *serv_port = "9190";
memset(&serv_addr, 0, sizeof(serv_addr)); //0으로 초기화(for sin_zero)
serv_addr.sin_family = AF_INET;
serv_addr.sin_addr.s_addr = htonl(INADDR_ANY);
serv_addr.sin_port = htons(atoi(serv_port));
//bind!!!
bind(serv_sock, (struct sockaddr*)&serv_addr, sizeof(serv_addr));
그냥 구조체의 멤버 세개를 위에서 배운 것들을 이용해 하나씩 채워준다.
위 코드에서 짚어볼만한 점들은 다음과 같다.
0. serv_addr을 0으로 초기화
: 어차피 덮어쓸 영역인데 0으로 굳이 초기화 해야되나 싶을 수도 있다. 하지만 위에서 언급했듯 sin_zero member는 0으로 초기화돼야하기때문에 일단 다 0으로 밀어두고, 나머지 세 멤버를 잘 채우도록 하는 것이다. 그럼 자동으로 sin_zero는 0으로 초기화돼있다.
: sin_zero member를 반드시 0으로 초기화해야 하는 이유는,, 찾아봐도 굳이 0으로 초기화해야될 이유는 없는 것 같다. 그냥 지금까지 많은 코드가 그렇게 쓰였고, 예전부터 그렇게 권고해오고 있어서 안그러면 오류가 생기는 경우도 있다 정도인듯. 실제로 나도 이거 초기화 안해줘서 문제 됐던 적이 있었던 것 같음. 일단 그냥 0으로 초기화하는걸로 알고만 가자.
1. INADDR_ANY
: 현재 실행중인 컴퓨터의 IP 주소를 쓰겠다는 의미이다. 해당 host의 IP 주소가 여러 개라면 그 중 어디로 데이터가 들어와도 받을 수 있게 된다. 따라서 INADDR_ANY는 server program을 작성할 때 주로 사용한다. (위에서도 말했듯이 어차피 그 server의 주소는 이미 할당돼있으니 그걸 굳이 찾아서 적어주기보단 INADDR_ANY를 쓰면 편함. 다른 목적이 있다면 따로 적어주는게 맞겠지만)
2. IP 주소를 할당할 때 htonl, PORT 번호를 할당할 때 htons
: IP 주소는 32비트이므로 unsigned long을 반환하는 htonl, port 번호는 16비트이므로 unsigned short를 반환하는 htons 함수를 사용한다. 네트워크를 통해 해당 데이터를 보낼 것이므로 network의 byteordering인 big endian으로 변환해주는 것이다.
2-2. sin_family는 왜 변환 안 해주나?
: 얘는 network로 보내지는게 아니므로 변환해줄 필요가 없다. host에서 그냥 struct sockaddr * type의 polymorphic들을 구분할때 사용할 뿐이다. 답변 참고
2-1. 왜 write/read나 sendto/recvfrom을 이용한 일반적인 data 송수신에선 이런 byte-ordering 변환을 안하나?
: 왜냐하면 일반적인 경우 소켓 library나 protocol에서 적절하게 byte-ordering 변환을 해주기 때문이다. 일단 struct sockaddr_in에 데이터 넣을 때나 잘 해주면 된다.
3. bind 호출할때 " struct sockaddr* " 로 typecasting
: bind 함수는 struct sockaddr * type을 인자로 받기때문에 typecasting을 해서 전달해준다. struct sockaddr는 아래와 같이 선언된다. 보다시피 typecasting을 하면 AF 정보는 딱 맞아떨어지게 들어가고, 나머지 정보들은 sa_data 멤버에 몰아서 들어가게 된다. 이걸 뭐 bind 함수 안에서 나름대로 잘 해석해서 쓰나보다.
struct sockaddr
{
sa_family_t sin_family; //Address Family 정보
char sa_data[14]; //나머지 주소 정보
};
3-1. bind() 함수는 왜 바로 struct sockaddr_in을 사용하지 않는가?
: 왜냐하면 주소 정보가 sockaddr_in으로만 표현되는건 아니기 때문이다. sockaddr_in의 멤버를 보면 알 수 있듯이, 이 구조체는 IPv4 32비트 IP 주소를 저장하기에 적합하다. Address Family에는 얘 말고도 다양한 분류가 있기 때문에, bind 함수는 sockaddr이라는 general한 type으로 주소 정보를 받아오는 것이다. 나중에 다른 주소 체계가 도입되더라도 sockaddr_in이 했듯이 sockaddr type에 맞도록 padding 해주는 멤버를 추가하거나 하면 bind 함수를 사용할 수 있게 된다.
과제 코드를 실행할 때, server program은 port 번호만 입력받고 client program은 IP 주소와 port 번호 둘 다 입력받는다.
server는 INADDR_ANY를 이용해 자동으로 IP 주소를 할당받기 때문이다!!
이때 clinet에도 127.0.0.1 만을 IP 주소로 넘겨주는데, 이는 루프백 주소라고 하며 client를 실행하는 컴퓨터의 주소를 의미한다.
server와 client를 같은 host에서 실행시키므로 이 주소를 사용하는 것이다.
client는 다른 곳으로 연결 요청을 보낼 수도 있으므로, 한 host에서 상주하며 데이터를 받는 server와 달리 매번 IP 주소를 입력받도록 하는 것이다.
3. listen
#include <sys/socket.h>
int listen(int sock, int backlog);bind()로 socket을 주소 정보와 묶었다면, listen() 함수를 통해 해당 socket을 연결 요청 대기 상태로 만들 수 있다.
연결 요청도 데이터 전송이기때문에 이를 받아들이려면 마찬가지로 socket이 필요하다. 이렇게 연결 요청을 받아들이기 위한 소켓을 "서버 소켓" 혹은 "리스닝 소켓"이라고 한다. listen() 함수의 인자로 전달된 소켓은 리스닝 소켓이 된다.
첫번째 인자로 연결 요청 대기 상태로 두고자 하는, 즉 리스닝 소켓으로 만들고자 하는 소켓의 file descriptor을 전달한다.
두번째 인자로 연결 요청 대기 큐의 정보를 전달한다. 예를들어 5를 준다면, 클라이언트의 연결 요청을 최대 5개까지 대기시킬 수 있다.
성공 시 0, 실패 시 -1을 반환한다.
4. accept
#include <sys/socket.h>
int accept(int sock, struct sockaddr * addr, socklen_t * addrlen);리스닝 소켓(서버 소켓)을 첫번째 인자로 주면, 해당 소켓으로 연결 요청이 들어왔을 때 client 소켓과의 통신을 위한 별도의 소켓을 만들어주는 함수이다. (참고로, accept 할 땐 이미 3-way handshaking이 끝난 것이다.)
첫번째 인자로 리스닝 소켓(서버 소켓)의 file descriptor을 전달한다.
두번째 인자로 연결 요청한 client의 주소정보를 담을 변수의 주소를 전달한다. 함수 호출이 완료되면 이 변수에 client의 주소 정보가 채워진다.
세번째 인자로 두번째 인자의 크기 정보를 저장한 변수의 주소 값을 전달한다. 함수 호출이 완료되면 client 주소 정보의 길이가 byte 단위로 계산되어 채워진다.
성공 시 생성된 socket의 file descriptor를 반환하고, 실패 시 -1을 반환한다.
구체적으로, accept function은 연결 요청 큐에서 첫번째 커넥션을 가져와 소켓을 만들어 반환한다. 만약 대기중인 커넥션이 없다면 accept 함수는 새로운 커넥션이 생길 때까지 실행을 중지(Block)시킨다. [출처]
TCP Client
지금까지 살펴본 것은 TCP를 이용한 server program의 작성이었다. TCP Client Program은 아래와 같은 API 호출 순서를 갖는다.

Server는 소켓을 만든 뒤 bind하고 listen하고 accept했지만, Client는 그냥 소켓을 만든 뒤 원하는 곳으로 connect() 요청을 보내면 된다.
connect
#include <sys/socket.h>
int connect(int sock, const struct sockaddr * servaddr, socklen_t addrlen);client socket을 통해 두번째 인자로 전달하는 주소 정보로 연결 요청을 보낸다.
첫번째 인자로 통신에 사용할 client socket의 file descriptor를 전달한다.
두번째 인자로 연결 요청할 서버의 주소 정보를 전달한다.
세번째 인자로 두번째 인자의 크기 정보를 전달한다. (accept와 달리 포인터 형식으로 전달하지 않는다.)
주의할 점은, Server에서 listen() 함수가 호출된 이후여야 Client의 connect() 함수 호출이 유효하다는 것이다.
TCP Client는 그냥 소켓 만들어서 connect 호출한 이후, file로 취급되는 socket을 통해 read()/write()를 해주면 된다.
모든 socket은 IP 주소와 PORT 번호가 할당된다. server side에선 우리가 bind로 직접 할당해줬지만, client에선 그런 과정이 없었다.
왜냐하면 connect() 함수를 호출하면 자동으로 OS kernel에서 컴퓨터에 할당된 IP와 임의의 PORT 번호를 해당 socket에 할당해주기 때문이다.
TCT Server/Client Implementation example
https://www.geeksforgeeks.org/tcp-server-client-implementation-in-c/
Iterative 기반 Server/Client 구현

여러 client에서 연결 요청을 한다면 listening socket에 연결 요청이 여러개 쌓여있을테니(대기 큐에) 반복적으로 accept()를 호출하며 연결 요청이 온 client에 대해 통신 socket을 만드는 것이다. 그래서 listen()을 호출하도록 반복을 하면 안되고, 위 그림처럼 accept()를 호출하도록 반복해야한다.
이렇게 반복되도록 Server program을 작성한다면, 동시에 둘 이상의 Client는 처리할 수 없겠지만, 연속해서 들어오는 둘 이상의 Client는 처리할 수 있다.
Iterative echo 프로그램에 대한 자세한 코드는 과제를 참고하도록 하고... 몇가지만 짚어보자면,
일단 server.c에서 데이터를 읽어오고 다시 echo해주는 코드인 아래 놈은 문제가 없다. read한만큼 다시 write를 해주는데, 두번의 read->write를 하든 세번의 read->write를 하든 그대로 보내주는거니까 딱히 상관은 없다.
while((str_len = read(clnt_sock, message, BUF_SIZE)) != 0)
write(clnt_sock, message, str_len);
하지만 clinet.c의 아래 코드는 문제 발생의 소지가 있다.
write(sock, message, strlen(message));
str_len = read(sock, message, BUF_SIZE-1);
message[str_len] = 0;
printf("Message from server: %s\n", message);
TCP는 데이터 송수신에 경계가 존재하지 않는다.(stream-based 방식) 상대방 버퍼 사이즈를 보고 데이터의 일부분만 보내는 등 reliable communication을 위해 데이터를 딱딱 끊어서 보내고 받는게 아니다. 아니면 애초에 데이터 사이즈가 너무 크면 잘라서 보내기도 할 것이고...
따라서 TCP echo server 프로그램도 client로 받은 데이터를 한번에 다 보내지 않고 나눠서 보낼 가능성이 있지만, 얘는 문제될게 없다. 받을걸 몇번에 걸쳐서 돌려주든 결국 돌려주긴 하는거니까 echo program을 완성하는덴 문제가 없다.
단, TCP echo client 프로그램에선 문제가 발생할 수 있다. client가 a 만큼의 데이터를 보냈어도, server에선 그 a만큼의 데이터를 받더라도 몇번을 쪼개서 다시 client로 보낼 수도 있다. 그 사실을 알면 위 코드가 잘못됐다는걸 알 수 있다. 만약 server에서 "abc"를 받은 다음, "ab"를 먼저 client로 보내고 "c"를 나중에 따로 보낸다면 clinet에선 "ab"만 echo될 것이다. (실제론 한 만글자 정도는 돼야 이런 현상이 생길거라고 하심.)
즉, 위 코드는 "한 번의 read 함수호출로 앞서 전송된 문자열 전체를 읽어 들일 수 있다."는 잘못된 가정이 들어가있으므로 수정이 필요하다.
str_len = write(sock, message, strlen(message));
recv_len = 0;
while(recv_len<str_len) {
recv_cnt = read(sock, &message[recv_len], BUF_SIZE-1);
if (recv_cnt == -1)
error_handling("read() error!");
recv_len += recv_cnt;
}
message[recv_len] = 0;
printf("Message from server: %s\n", message);
따라서 이렇게 write할 때 얼마나 보냈는지 str_len에 기록해둔 뒤, 반복문으로 read를 할때마다 얼마나 읽었는지 누적하여 str_len 만큼 읽어오면 이를 출력하도록 한다. 이렇게 해야 위에서 언급한 것과 같은 문제가 발생하지 않는다.
TCP 이론
TCP는 Reliable Control을 지원하는 Protocol이다.
1. Error control
2. Flow control : sliding window protocol
3. Congestion control
> TCP Socket의 입출력 Buffer

위 그림과 같이 TCP socket에는 입출력 버퍼가 각각 존재한다. 입출력 버퍼는 소켓 생성시 자동으로 생성되며, 이 버퍼 덕분에 슬라이딩 윈도우 포로토콜(상대 버퍼 크기를 봐가며 데이터를 보내는 것)이 가능해 버퍼가 차고 넘치는 상황이 발생하지 않는다.
Socket을 닫아도 출력 버퍼에 데이터가 남아있다면 계속해서 전송이 이루어진다. 반면 입력 버퍼에 남아있는 데이터는 소멸된다.
> TCP 내부 동작 1 : 상대 소켓과 연결

SEQ는 지금 보내는 packet에 부여하는 번호이다. ACK는 다음번에 보내달라고 요청하는 packet의 번호이다. 따라서 ACK는 이전 packet을 잘 받았다는 신호의 의미도 있다.
연결 요청을 할 때도 이 SEQ와 ACK를 이용해 각 packet을 잘 받았는지 확인하도록 한다.
<3-way handshaking>
SYN -> SYN+ACK -> ACK 로 control flag를 설정해 연결 요청을 하며, SEQ와 ACK로도 값을 확인한다. (참고로, 전자의 ACK는 control flag를 말하는 것이고, 후자의 ACK는 Acknowledgement number를 말하는 것이다.)
Q. 어차피 SYN -> SYN+ACK -> ACK로 진행상태 확인하면 되지 않나? 왜 SEQ number랑 ACK number도 쓰는건지?
A. 찾아보니 그냥 안전하게 데이터 무결성 등을 확인하려고 SEQ/ACK number도 확인하는 것 같다. 데이터를 주고 받을 때 SEQ/ACK number로 reliable control을 하는 것이 일단 기본이고, 그게 연결 요청이거나 종료 요청이거나 특수한 경우라면 control flag를 설정해주는 것 같다.
> TCP 내부 동작 2 : 상대 소켓과 데이터 송수신

데이터를 주고 받을 때 위에서 말했듯 SEQ number와 ACK number를 이용해 packet 전송 유무, 데이터 손실 유무를 확인할 수 있다.
host B에선 매번 데이터를 잘 받았다는 의미로 ACK number의 값을 SEQ number+데이터크기+1 만큼 보내준다. 그럼 host A는 그 ACK number부터 데이터를 보내주는 것이다.
위 그림에서 보다시피 중간에 어떤 이유로 데이터가 host B에 도달하지 못한다면 host A는 ACK number를 받지 못할 것이다. host A에선 SEQ number를 보낼때마다 타이머를 작동시킨다, 특정 시간이 지나도 ACK number를 받지 못한다면 host A에서는 다시 데이터를 전송하고, 이번엔 host B에 데이터가 잘 도달했다면 host A는 ACK number를 받을 수 있다.
> TCP 내부 동작 3 : 상대 소켓과 연결 종료

<4-way handshaking>
FIN -> ACK -> FIN -> ACK, 총 4번 패킷을 주고 받으며 연결 종료를 한다.
host A에서 FIN을 보내고 host B에서 ACK와 FIN이 ACK number는 똑같이 보내고 SEQ number는 7500과 7501을 보낸다는 것 말고는 딱히 짚을만한게 없는 듯.
close()를 통해 socket을 닫으면 위와 같은 일이 일어나는 것이다. 4-way handshaking을 하는 이유는 일방적 종료로 인한 데이터 손실을 막기 위함이다.
좀 더 자세히 설명하자면, 위 4개 패킷이 모두 오가야 완전히 연결이 종료되는 것이다. host A에서 더 이상 보낼 데이터가 없다고 판단하여 host B로 FIN을 보내도 아직 연결은 돼있는 상태이다. host B에서 만약 FIN을 받았는데 보낼 데이터가 남아있다면, 아직 연결상태이기 때문에 host A에 남은 데이터를 보낼 수 있다. 그렇게 host B도 데이터를 다 보냈다면, 그제서야 FIN을 host A에 보냄으로써 TCP 종료에 동의하고 완전히 연결이 종료되는 것이다. 일방적 종료가 아닌, 4번이나 패킷을 주고받으며 서로 합의하에 보낼거 다 보내고 종료되도록 하여 데이터 손실을 막는다.
※ 주의 ※
하지만!! 바로 위에서 말한건 TCP 연결 종료할 때 이론적인 얘기고, 만약 close()나 closesocket()으로 연결을 종료한다면 데이터 손실이 발생할 수도 있다.
왜냐하면 close()를 해버리면 FIN을 보내는건 맞지만 아예 socket을 닫아버리기 때문에 상대방이 보낼 데이터가 남아있더라도 그걸 받을 수가 없다.
따라서 Half-Close라는 것을 활용해야 깔끔하게 종료할 수 있다. 이는 다음 글에서 설명한다.
'수업 > Network Programming' 카테고리의 다른 글
| [Network Programming] Domain Name System(DNS) (0) | 2023.05.28 |
|---|---|
| [Network Programming] TCP 기반 Half-close (0) | 2023.05.28 |
| [Network Programming] UDP socket 통신 (0) | 2023.05.27 |
| [Network Programming] Network Socket Programming 개요/기초 (0) | 2023.05.25 |
| [Network Programming] TCP/IP (0) | 2023.05.22 |