컴퓨터의 언어로 쓰인 단어를 instructions라고 하고, 그 vocabulary를 instruction set이라 한다.
사람이 읽을 수 있는 instruction과 기계가 읽을 수 있는 instruction, 두가지 형태를 가진다. 기계어 형태, assembly어 형태
이런 instruction set이 바로 hardware와 software 사이 interface이다.
Instruction은 Opcode(operation code)와 Operands 두가지 부분으로 나뉜다.
Opcode에 따라 Operands에 연산을 수행하는 것이다.
Instruction set이 computer마다 다른 것은 맞지만, 그렇게 다르진 않다.
왜냐하면 모든 computer는 비슷한 하드웨어 기술로 만들어지고, 제공해야 하는 기능도 비슷하다.
그리고 computer designer들은 오랫동안 "hardware와 compier를 만들기 쉽게하고 performance를 극대화시키며 cost/energy를 최소화시키는 language를 찾는 것"이 목표였기 때문이다.
즉, 공통의 목표를 가지고 비슷한 기술을 공유해 비슷한 기능을 제공하기때문에 instruction set은 모두 비슷비슷하다.
ISA는 hardware implementation과는 별개이다. 즉, ISA는 hardware의 specification인 셈이다.
즉 이런 ISA를 기반으로 직접 hardware를 구현한 것을 Microarchitecture(μarch)라고 한다.
software와는 관련없이 hardware단에서 구현되는 모든 것들(pipelining, memory access scheduling, ...)을 말한다.
예를들어 x86 ISA로 구현된 놈들은 286, 386, 486, Pentium, Pentium Pro, Pentium 4, ... 등이 있다.
CISC vs. RISC
Instruction set은 크게 두 종류로 나뉜다.
- CISC(Complex Instruction Set Computer)
- RISC(Reduced Instruction Set Computer)
CISC는 강력한 instruction set을 만든다. 무슨 말이냐면, 간단한 기능만 구현하는 것이 아니라 복잡한 기능들도 hardware단에서 instruction set에 구현해두는 것이다.
장점: assembly programming이 매우 간단해진다. 이미 구현된 기능이 많을 것이므로, 그냥 code한줄로 끝내버릴 수 있다.
또 compiler도 간단해지고, instruction memory 사용도 줄어든다.
단점: 하지만, CPU를 design하는 것이 더 어려워진다. 각종 기능을 hardware단에서 구현해야하기 때문이다.
과거 x86같은 놈이 CISC의 한 종류이다.
그래서 "instruction은 최대한 간단하고 작게 구현하고, software가 복잡한 작업을 처리하도록 하는 개념"이 등장했다.
RISC는 간단한 연산 작업들만 지원한다. 그리고 복잡한 작업은 software단에서 이리저리 작성해서 처리하도록 한다.
장점: CPU design이 간단해지고, instruction set이 작아져 "clock speed가 올라간다."
단점: assmbly language가 더 복잡하고 길어지고, memory 사용이 증가한다는 단점이 있긴하다.
즉, CPU time 측면에서 보자면 CISC는 IC를 줄이지만 CPI를 증가시키고, RISC는 CPI를 줄이지만 IC를 증가시킨다.
둘 중 누가 더 나은지는 아직 결판나진 않았다.(교수님께서 그렇게 말씀하심)
RISC-V는 RISC 원리에 입각해 만들어진 open standard ISA이다.
RISC-V
RISC-V의 register size는 32bits와 64bits가 있다. (수업은 64bits 기준으로 함, 근데 책에선 32bits 기준이네..ㅋㅋ)
RISC-V에선 32bits를 WORD, 64bits를 DOUBLEWORD라고 한다. (x86에선 16이 word, 32가 dword)
(일반 컴퓨터에서 말할땐 register 비트수를 보통 word라고 함.)
registers의 총 개수는 32개로 x0~x31 로 이름붙인다.
register개수가 32개인 것은 hardware design의 기초 원리 3가지 중 한가지인
"Smaller is faster"
를 기반으로 하는 것이다.
register 개수가 늘어나면 전기신호도 길어져서 clock cycle이 증가한다.
뭐 무조건 작은게 빠르다고 볼 순 없지만, 32개로 한 이유는 다음과 같다. (1)clock cycle을 빨리하려는 designer와 register가 많으면 좋은 프로그래머 사이 밸런스를 맞춘 것이고, (2)instruction format의 bits 개수 때문이다.

RISC-V instruction 각 line은 최대 하나의 instruction만 가질 수 있다.
RISC-V에는 C형식의 `//` comment를 작성할 수 있다.
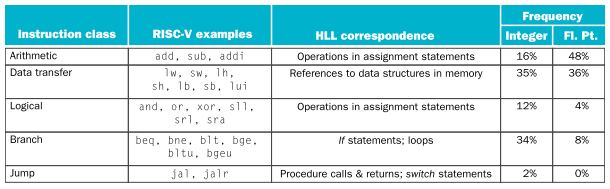
RISC-V 기초 instructions
▶ add rd, rs1, rs2
RISC-V의 arithmetic instruction은 모두 "3개"의 "register operands"를 필요로 한다.
딱 3개의 operator만을 받는 것은 hardware design의 기초 원리 3가지 중 한가지인
"Simplicity favors regularity"
를 기반으로 하는 것이다.
인자 개수대로 instruction을 정의하는 것보다 딱 한가지 경우만 보는 것이 간단하다.
ex) f = (g+h) - (i+j); 는 아래와 같이 compile된다. (temp 사용)
add t0, g, h
add t1, i, j
sub f, t0, t1
C나 다른 언어로 프로그램을 작성해봤겠지만, register 32개로는 모든 변수를 표현하기 부족하다.
따라서 memory의 공간을 활용해야하는데, 이때 data transfer instructions을 사용할 수 있다.
memory의 data를 register로 가져오는 load instructions와
register의 data를 memory로 보내는 store insturcitons이 있다.
▶ ld rd, offset(rs1)
위 instruction의 의미: 'rs1에 담긴 값+offset' 주소로가서 doubleword(8bytes) 크기만큼 데이터를 읽어와 rd에 저장한다.
이외에 byte만큼 읽어오는 lb, word(4bytes)만큼 읽어오는 lw가 있다.
▶ sd rd, offset(rs1)
위 instruction의 의미: rd에서 doubleword(8bytes) 크기만큼 데이터를 읽어 'rs1에 담긴 값+offset' 주소에 저장한다.
이외에 byte만큼 저장하는 sb, word(4bytes)만큼 저장하는 sw가 있다.
offset은 byte 단위이다. C pointer arithmetic처럼 생각하면 안된다. (rs1 위치의 놈은 base register라고 한다.)
또 64bits register라면 offset은 되도록 8의 배수로 작성해야한다. 물론 데이터 접근은 1byte 단위로 가능하지만, 주로 register 크기에 맞게 데이터를 메모리에 읽고 쓰고 하므로 보통 그렇게 맞춘다.
x86에선 메모리 주소를 이용해 곧바로 그 주소의 값을 사용할 수 있다.
하지만 RISC-V는 x86처럼 rs1 위치에 바로 memory 주소는 사용하지 못한다.
지원하는 addressing mode 범위가 달라 애초에 RISC-V의 operands로 memory에 있는 값은 사용할 수 없다.(책p.162/이 글 하단부 addressing mode 참고)
(x86은 mov로 다 퉁칠 수도 있는데 그런게 아마 CISC라 그런가보다.)
▶ addi rd, rs1, imm
위 instruction의 의미: rs1의 값과 imm 상수값을 더해 rd에 저장한다.
※ Immediate operand
이렇게 i가 붙은 instruction은 보통 immediate operands를 허용한다.
이런 류의 instruction이 없다면 상수가 쓰일때 memory에 숫자를 저장해뒀다가 load를 해서 써야한다.
하지만 load/store같은 memory 접근 연산은 비교적 느리기때문에 최소화하는게 좋다.
상수가 쓰이는 경우는 꽤 많은데, SPEC CPU2006 benchmarks의 절반 이상의 RISC-V arithmetic instructions이 상수를 사용한다.
그렇기 때문에 immediate value를 곧바로 instruction 내부 자체에 삽입하는 `addi` 같은 instruction을 제공한다.
이 덕분에 memory에 접근하지 않아도 되니 더 적은 에너지를 사용해 더 빠르게 명령이 수행된다.(common case fast)
instruction 2진수 기계어 자체에 바로 숫자가 올라가므로 너무 큰 숫자는 사용하지 못한다.
※ Constant Zero (x0)
x0 register에는 0을 저장해 사용한다.(수정불가)
0은 자주 쓰이는 값이기때문에 memory에 저장하지않고 가장 빠르게 접근할 수 있는 register에 저장해 사용한다.
ex1) move data between register : add x22, x21, x0
ex2) negate the value : sub x22, x0, x22
※ Spilling
많은 프로그램의 변수는 register 개수보다 훨씬 많다.
그러므로 compiler는 많이 쓰이는 값들을 register가 저장하도록하고 나머지 값들은 메모리에 저장해서 성능을 높인다.
비교적 덜 쓰이거나 나중에 쓰이는 값은 memory로 흘려보내버리는데, 이 과정을 spilling이라고 한다.
data는 register에 있어야 유용하다.
접근이 빠른건 둘째치고, (RISC-V의 경우) 곧바로 instruction의 값으로 활용할 수 있기 때문이다.
또 register에 접근하는 것이 energy도 절약한다.
그러므로 "높은 performance와 energy 절약"을 하려면 "ISA는 충분한 register를 제공"해야하고, "compiler는 registers를 효율적으로 사용"해야한다.
※ Endian
(계속 같은 크기로 memory에 data를 읽고 쓴다면 신경쓰지않아도 되지만,, 그래도 알고있어야함)
RISC-V는 byte ordering에서 little endian을 사용한다.
오해하면 안되는게, array나 structure의 members같은건 항상 일정하게 순서대로 저장된다.
little endian일 경우 "한 data 내부"에서 byte 순서(byte ordering)만 반대인 것이다.(bit ordering은 보통 big endian임)
little endian/big endian 둘 다 각각의 장단점이 있어서 쓰이는 장소가 각각 다르다.

※ 변수 선언
'valnam: .dword 4` 같은 형식으로 변수선언을 할 수 있는데,
RISC-V 자체 instruction이라기보다 시뮬레이터에서 어떻게 잘 번역되도록 지원해주는 것 같음.
※ Pseudo Instruction
특정 기능들을 제공하는 instruction이다.
실제 instruction은 아니고, 해당 pseudo instruction에 맞는 기능을 제공하도록 실제 instructions으로 변환된다.
예를들어 `nop`이란 pseudo instruction은 사실 `addi x0,x0,0`이란 실제 instruction으로 변경되는 것이다.
`li rd, immediate` : pseudo instructions 중 하나로, rd에 immediate 값을 load한다.(기존 load를 적용하려면 memory에 있는 것이어야했음)
▷지식
Java는 portability 증가를 위해 JVM이라는 software interpreter 위에서 돌아가는 놈이다.
이 interpreter의 instruction set이 Java bytecode이다.
같은 logic의 C program 성능과 비슷해지기위해 최근에는 Java system은 bytecode를 그 hardware의 native instruction set으로 변환한다.(뭐 그래도 Java에서 나온게 기존 C에서 나온 코드보단 길겠지)
Signed and Unsigned Number
LSB: 가장 낮은 자리수 bit, 가장 오른쪽 bit
MSB: 가장 높은 자리수 bit, 가장 왼쪽 bit
Signed number를 표현할땐 MSB를 부호비트로 사용한다.
그리고 음수 계산의 편리를 위해 음수는 2의 보수 형태로 표현한다. (sign and magnitude 방식 아님)
(binary bit pattern은 숫자를 표현하는 것일 뿐이다. 우리가 지정하기 나름)
2의 보수에 관해, 진수 변환에 관해(내용 중에 있음)
(참고로 2의 보수 변경할땐 음수->양수이든 양수->음수이든 양방향 모두 마지막에 +1을 한다.(-1 없음))
Signed and Magnitude의 단점
1. 0을 두가지 방식으로 표현해서 range에서 1만큼 손해
2. sign 비트를 어디 위치시킬지 애매
3. 뺄셈 연산시 2's complement에 비해 과정 복잡
Sign Extension ★
숫자가 확장돼도 부호를 유지하는 것을 말한다.
16bits(halfword) 공간에 저장된 `-2`를 32bits register에 load한다고 해보자. 그대로 load하고 앞부분은 0으로 채워버리면, 아예 다른 숫자가 돼버린다.
양수면 0으로 채워도 상관없지만, 음수라면 앞부분을 모두 1로 채워줘야 숫자가 그대로 유지된다.(해보면 앎)
이렇게 부호를 유지해주는 Sign Extension을 수행하는 load는 `lb`, `lh`, `lw`,... 같이 우리가 알던 load 명령어들이다.
Sign을 유지하고 싶지 않다면 `lbu` 같은 unsigned 버전을 이용하면 된다.
숫자가 아닌 data라면 sign 앞을 1로 채우는 짓을 하면 오히려 data가 바뀌므로 unsigned version을 사용한다.
해당 data가 어떤 유형의 data인지, 숫자인지 등을 판단하는건 programmer 본인이다.
C 프로그램에선 bytes를 숫자보단 문자를 나타내는데 더 많이 사용하므로 `lbu` 가 실제로 거의 대부분 쓰인다.
이런 구분이 C에도 반영되어 unsigned와 signed 버전이 나뉜 것이다.
Instruction Representation
Assembly Instruction ↔ Machine Instruction
`add x2, x3, x4` 같은 것은 사람이 읽기 쉬운 assembly 형태이다. 하지만 실제로 컴퓨터는 이진수 숫자를 이용한다.
둘의 모양만 다르고 본질은 같은 것이다. 즉, assembly instruction과 동치인 Machine Instruction이 있다.
machine instruction은 32bits로 고정된다.(제너럴 register가 64bits인것관 상관없는듯 IR이 32bits로 고정인건가?)
32bit가 의미에 따라 여러 부분으로 나뉘는데 각 부분을 field라고 한다.
instruction마다 type이 달라서 field의 의미도 조금씩 다른데 이런 layout을 instruction format이라 한다.
<각 field별 의미>
opcode : instruction의 기본 operation을 의미한다. 쉽게말해 어떤 종류의 연산인지 식별해준다.
rd : register destination operand, operation의 결과를 저장하는 곳이라는 의미이다.
funct3 : 추가 opcode field
rs1 : The first register source operand
rs2 : The second register source operand
funct7 : 추가 opcode field
opcode, funct3, funct7을 통해 어떤 명령어인지 식별한다.
정확히 뭔지는 잘 모르겠으나, 일단 opcode를 통해 instruction type/format을 알 수 있고, 이를 통해 instruction 뒷부분을 어떻게 해석할지 등을 결정한다. 이후 정확히 어떤 instruction인지는 funct를 통해 아는 것 같다.
rd, rs 영역은 5bits이다. 32개 registers를 표현하기 딱 맞다. 여기서 하나라도 추가되면 register field가 모두 늘어난다.
그래서 대부분 ISA에선 16개 혹은 32개의 general-purpose registers를 사용한다. (2의 지수승으로 쓰네)
<Assembly → Machine Instruction>
어떻게 각 명령어가 변환되어 들어가는지 보고싶으면 이런 assembly 명령어 목록을 보면 된다.
예를들어 add(rd, rs1, rs2) 는 이 글 바로 아래 사진에 보이는대로 각 field에 rd, rs1, rs2가 각각 들어간다.
대부분 assembly에 적힌 것의 역순으로 들어가고, store 명령어만 좀 순서가 다르다.
R-type

add, sub가 R-type instruction format을 가진다.
assembly에서의 인자 : rd, rs1, rs2
I-type

addi, ld가 I-type instruction format을 가진다.
assembly에서의 인자 : rd, rs1, immediate
ld도 immediate offset을 받기때문에 여기로 분류됨. 세부분류는 다름.
immediate는 12bits인데, 2의 보수 표현이 들어간다. 따라서 음수도 가능하다. -2^11 ~ 2^11-1까지 표현 가능.
(subi가 없는 이유는 immediate에 음수가 들어갈 수 있으니 addi로 다 처리가능하기때문)
S-type

sd 같은 store 연산이 S-type instruction format을 가진다.
assembly에서의 인자 : rs2, rs1
(주의) sd은 machine instruction으로 변환될때 ld와 register 순서가 다르다.
immediate값은 심플하게 두 part로 쪼개져 들어간다. 7bits에 높은 자릿수 부분을, 5bits에 낮은 자릿수 부분을 넣는다.
(쉽게 그냥 이진수로 적고 쪼개서 왼쪽놈은 왼쪽, 오른쪽놈은 오른쪽에 넣으면 됨)
종합

같은 길이로 통일하고 최대한 format을 유지하는 것이 hardware 설계의 수고를 덜어준다.
Simplicity favors regularity / Good design demands good compromises
우선 R과 I를 보자. opcode ~ rs1 까지는 그대로 형식을 유지한다. 그리고 뒷부분을 immediate를 표현하도록 하여 최대한 형식을 유지했다. (funct7은 필요없나보다)
R과 S를 보자. S에선 rd가 없어졌는데, destination이 register가 아닌 메모리이기 때문이다. 한 register의 값을 다른 register에 담긴 주소값+offset에 넣어야하니, 두 operand가 모두 source에 해당한다. 그래서 rd를 없애고 그 자리를 immediate가 쪼개져서 들어간다. (offset을 받아야하니 imm operand가 필요)
그냥 자리를 땡기면 imm을 안 쪼개도 되지않나 생각할 수 있는데, rs1과 rs2의 자리를 유지하는게 더 낫다.
즉, 각 field의 "역할"과 "위치"를 최대한 유지하는 쪽으로 가는 것이 hardware 복잡성을 줄이기 때문에 위같이 설계한다.
Q. 왜 S-type에선 rs1과 rs2의 위치가 유지될까? (ld 연산과 비교하면 순서가 다름)
A. I-type에서 ld가 쓰일때 rs1이 하는 역할을 유지하기 위해서인 것 같다.
ld에서 rs1은 "메모리에서의 base 주소"를 가리킨다.
sd 에서도 이러한 rs1 위치의 역할을 유지하면 format이 일정해진다. 아마 그 이유로 store 연산이 machine instruction으로 바뀔땐 rs1, rs2 위치가 다른 것과 다르게 순서대로 들어가는 게 아닐까 생각한다.
Q. 왜 machine instruction으로 바뀔때 순서가 저렇게 될까?
A. (정확한 HW지식은 없지만.. 나름 정리해봄)
일단 machine instruction의 순서와 assembly language에서의 순서는 정하기 나름이다. machine instruction과 대응되도록 CPU 동작 등을 설계할 것이고, 우리가 쓰는 assembly 언어는 영어로 1:1 대응되게 바꾼 것일 뿐이다. 그러니 의미가 중요하지 순서가 중요한게 아니다. 그래서 RISC-V에서도 보면 assembly에 대응하는 machine instruction 코드 내의 순서가 제각각이다.
Q. 그럼 machine instruction에서 opcode가 제일 뒤에, 가장 낮은 자리수에 오는데 왜 그럴까?
A. (안 그런 나라도 있지만)대한민국에선 글을 좌→우로 읽는다. 숫자도 마찬가지로 그 영향을 받아서 좌우로 읽는게 매우 당연해 보인다. 하지만 잘 생각해보면 낮은 자리수부터 읽든 높은 자리수부터 읽든 크게 상관은 없다. "천.이십.삼"이나 "삼.이십.천"이나 어색하긴하나 의미가 달라지거나 하진 않는다.(잘 끊어읽는다면)
그리고 숫자의 관점에서 보자면 오히려 낮은 자리수부터 읽는게 더 자연스러운게 아닌가 생각된다. 덧셈 같은 연산을 할때도 그렇고,, "문자"로 표현된 숫자가 아닌 오직 "숫자"의 관점에서만 보자면 그게 더 자연스럽다고 생각된다.
아마 HW도 그렇게 낮은 자리수부터 읽어오도록 설계되었기에 가장 먼저 읽혀야하는 opcode가 낮은 자리수에 온게 아닐까 생각한다.. 먼저 읽혀야 이게 어떤 operation인지, 어떤 format인지 알 수 있어서 다음 숫자를 해석할 수 있다...
뭐 솔직히 하드웨어를 높은 자릿수부터 읽도록 설계한다면 opcode가 높은 자릿수에 와도 상관없을 것이다, 실제로 MIPS는 opcode가 높은 자리에 오는 instruction도 있다.
역사적 이유 때문인지 뭐인진 모르겠지만,, 낮은 자릿수부터 instruction을 읽어오고, 그래서 opcode는 낮은 자릿수에 들어가는 것... 정도만 알자.
(참고로 instruction을 다루는 register가 따로 있다. 보통 메모리의 instruction들을 그 register가 읽어서 처리한다.)
Q. instruction이 저장될땐 어떻게 저장되지? 위 format에서 다시 little endian이 적용돼서 바이트 단위로 거꾸로 저장되나?
A. YES, 직접 rars로 instruction이 어떻게 저장되는지 보니까 위 instruction format이 little endian으로 들어간다. 위 고찰대로면 opcode가 먼저 읽혀야하니 (그리고 컴퓨터는 낮은 주소부터 데이터를 읽어올테니) 당연히 낮은 주소에 instruction의 낮은 자리 값들이 들어가줘야한다.
(이게 자연스러운데 언뜻봐선 어색해보임.. 참고로 rars로 볼때 데이터들 4바이트씩 낮은 자리를 뒤에 나오게 보여주니까 유의하기)
현대 컴퓨터는 두가지 key principles 위에 만들어진다.
1. Instructions은 숫자로 표현된다.
2. Programs은 data처럼 memory에 저장돼 읽고 쓰인다.
이런 원리 덕에 stored-program concept이 나왔다. 즉, processor가 프로그램이든 데이터든 소스코드든 뭐든 전부 메모리에 올려서 동등하게 대할 수 있다. 이덕에 computer system의 H/W는 물론이고 S/W도 매우 간단해졌다.
위 원리의 또 다른 결과로는, 상업적인 관점에서, 이미 만들어져있는 software들은 이미 존재하는 instruction set과 호환됐기때문에 ISA가 우후죽순 생겨나진 않고 작은 규모로 유지돼왔다.
Logical Operations
| Logical Operations | RISC-V Instructions |
| Shift Left Logical | sll, slli |
| Shift Right Logical | srl, srli |
| Shift Right Arithmetic | sra, srai |
| Bit-by-Bit AND | and, andi |
| Bit-by-Bit OR | or, ori |
| Bit-by-Bit XOR | xor, xori |
| Bit-by-Bit NOT | xori |
(Shift Left 일지 Right일지로 sl, sr까지 결정나고 그 다음 Arithmetic일지 Logical일지로 뒤에 l일지 a일지 정해짐)
shift 연산은 사실상 2의 n제곱을 곱하고 나누는 효과를 준다. 즉 곱셈, 나눗셈을 할 수 있다.
오른쪽으로 shift할때, Logical 연산은 Sign Extension을 지원하지 않고, Arithmetic 연산은 Sign Extension을 지원한다.
즉 세번째가 l이면 앞부분이 무조건 0으로 채워지고, a이면 부호에따라 0 or 1이 채워진다.
AND, OR, XOR, NOT 연산은 bit-by-bit 연산을 한다. (XOR은 비트가 같은 숫자면 0, 다른 숫자면 1을 출력)
마찬가지로 R-type 버전(rd, rs1, rs2)도 있지만, I-type 버전도 있다.
주요 기능으론,
1. AND는 특정 field를 isolate 시킬 수 있다. opcode 부분만 뽑고 싶다면, 000..0011111와 AND 연산을 하면 된다.
이렇게 AND로 특정 부분을 뽑아내기위해 사용되는 bit pattern을 mask라고 부른다.
(참고로 isolate는 왼쪽으로 shift시키고, 다시 오른쪽으로 shift 시킴으로써"도" 수행할 수도 있다. 단, AND는 추출한 field가 본래 위치에 있도록하고, shift는 추출한 field를 가장 우측에 위치하도록 한다.)
2. 111...111과 XOR을 하는 것은 NOT 연산을 하는 것과 같다.
(그래서 사실 NOT은 실제 Instruction이 아닌, XOR로 구현된 pseudo instruction이다.)
<Machine Instruction of Logical Operations>

imm값을 사용하지 않는 그냥 일반적인 shift/logic operations은 보다시피 R-type이다.

위는 imm 값을 사용한 "Shift" Operations의 Instruction Format인데, 이는 I-type으로 분류된다.
shift 연산은 애초에 register 위에 수행되므로 32bits 크기 register라 가정한다면 imm의 공간이 5비트보다 클 필요가 없다.
(책) 그래서 I-type을 조금 변형해 imm의 높은 자리수로 사용하던 부분은 funct7로 쓰인다.
Q. 수업에서 사용하는 64bits 크기 register라면 어떻게 될까?

Machine Instruction 길이가 변하는게 아니라, 보다시피 funct7의 비트 하나를 가져와 2^6-1 = 63 까지 표현하도록 해준다.
Making Decisions
computer와 일반 계산기의 차이는 "결정을 내리는 능력"에서 온다.
조건에 따라 PC(Program Counter)가 branch(jump)를 하도록 하는 Instructions를 Conditional branches라고 한다.
(모든 Branch Instructions는 B-type으로 분류된다. 책/수업 모두 딱히 언급하진 않아서 자세한 얘기는 패스)
얘네는 if문 같은 조건문에도 활용되지만, for문 같은 반복문에도 활용된다.
- beq rs1, rs2, L1
- bne rs1, rs2, L1
- blt, bge, ...
branch if equal, branch if not equal, branch if less than, branch if greater than or equal
모두 rs1 기준으로 하는 말이다. 비교되는 값들은 모두 2의보수 signed 형태로 간주된다.
얘도 당연히 signed인지 unsigned인지 구분할 필요가 있다. (다시 말하자면, sign 유무는 프로그래머가 판단하는 것이다.)
아래 unsigend 버전을 이용하면 된다.
- bltu, bgeu, ...
<if문 예시 code>
if (i==j)
f = g + h;
else
f = g - h;
//를 컴파일,,,
//f:x19, g:x20, h:x21, i:x22, j:x23 이라 가정
bne x22, x23, Else
add x19, x20, x21
beq x0,x0, Exit
Else: sub x19, x20, x21
Exit:
<while문 예시>
while (save[i] == k)
i += 1;
//컴파일하면,,
//i:x22, k:x24, base of save:x25 이라 가정
//배열 크기는 doubleword(64bits)라 가정 (시험에서도 별말없으면 dword로 가정하라고 하심)
Loop: slli x10, x22, 3 #dword이므로 한칸에 8bytes
add x10, x10, x25 #x10에 save[i]의 진짜 주소가 남는다.
ld x9, 0(x10)
bne x9, x24, Exit #여기까지가 save[i]==k 과정이다.
addi x22, x22, 1
beq x0, x0, Loop
Exit:
SPEC에서 저렇게 Label을 사용하도록 명시되진 않는다.
보면 그냥 해당 instruction 위치로부터 몇 byte 떨어진 곳의 명령어인지 offset을 저장한다고 나온다.
즉, 이렇게 간단하게 영어로 labeling을 하는 것은 simulator 같은데서 알아서 변환되도록 지원해주는 기능이 아닐까 생각한다.
RISC-V는 branch 문을 종류별로 제공한다. 이렇게 추가 branch 명령어를 제공하지 않고 아래와 같이 할 수도 있다.
1. MIPS의 경우, register에 비교연산의 값을 넣고 그 값과 beq, bne 등을 이용해 branch 한다.
processor의 datapath는 간단해지지만, 더 많은 instructions으로 해당 과정을 표현해야한다.
2. ARM의 Instruction sets과 x86은 condition codes(flags)라는 추가 비트를 이용해 negative,zero,overflow 등의 정보를 저장한다. 그리고 이 flag 정보를 바탕으로 branch 한다.
하지만 이는 많은 instructions이 있을때 pipelined execution을 어렵게 만드는 dependencies가 발생할 수 있다.
Bounds Check
signed number를 unsigned number로 취급함으로써 0<=x< y 같은 연산의 cost를 줄일 수 있다.
특히 Index out of bound를 체크할때 유용한데, 예시를 보면 바로 이해된다.
ex) x20이 x11보다 크고, 0보다 작은지 판단해보자.
원래라면 비교를 두번 해야하지만, bgeu x20, x11, IndexOutOfBounds 로 한번에 판단할 수 있다.
(배열에서 index가 범위를 넘어가도 접근되는 언어가 몇개있다. C가 그럼(UB이긴했던거같은데쨌든)... 여기선 어셈블리단에서 코딩하므로 그걸 허용할지말지 정하는 것)
Switch 문
Switch는 if-then-else 처럼 Conditional Branches 막 섞어서 compile되게 하면 된다.
하지만, case문은 정수형으로 딱딱 떨어지므로 점프할 주소의 table로 관리하면 더 효율적이다.
이를 branch address table(branch table)이라 한다.
switch 문에 주어진 값을 이용해 table index를 찾고, 점프할 코드의 주소들인 그 index의 값을 이용해 branch한다.
이를 위해 해당 주소로 점프할 indirect jump(unconditional branch) instruction이 필요한데, jalr이 그 기능을 한다.
(jalr말고 "beq x0, x0, L"이나 "jal x0, L" 써도 되긴 할듯)
Supporting Procedures
Procedure(function)은 software에서 abstraction을 구현하는 한 방법이다.
아래 단계를 거쳐 procedure을 실행할 수 있다.
1. Procedure이 접근할 수 있는 위치에 parameters을 삽입: 주로 x10-x17 reg 이용
2. control을 procedure로 이동: PC+4를 x1에 저장하고, PC를 이동시킴
3. 해당 procedure에 필요한 storage 공간 할당: fp저장공간, 기존reg백업공간, 지역변수공간 등 필요공간 stack에 할당
4. 작업 수행
5. Calling program이 접근할 수 잇는 위치에 result value를 삽입
6. control을 기존 위치로 반환: x1의 값으로 PC 이동시킴
register가 가장 빠른 저장소이므로 최대한 활용한다. RISC-V에선 보통 아래와 같은 관습을 따른다.
x10-x17 : procedure 호출 시 parameter와 return value를 위해 사용
x1 : "return address" 저장을 위해 사용 ("여러 곳에서 procedure을 호출할 수 있기때문에" 다시 돌아가려면 필요하다.)

또 위 register들과는 별개로 존재하는 추가 register도 있다.
PC : Program Counter, 현재 실행중인 instruction 주소값을 가진다. instruction address register라고도 한다.
(program이 진행되며 계속 +4가 되는 register이다.)
1. Procedure이 접근할 수 있는 위치에 parameters을 삽입
이건 바로 위에서 봤듯 보통 x10-x17 register를 이용해 진행된다.
만약 위 8개 registers로 (1)부족하거나 (2)reg에 들어갈 수 없는 큰 자료형(ex.배열,구조체)이라면, stack에 할당받아 매개변수를 넘겨준다.(이때는 fp를 활용하지 않음)
2. Control을 procedure로 이동
- jal rd, imm21
jal instruction은 (1)rd에 PC+4의 값을 저장하고, (2)imm21 위치로 branch한다.
rd에는 보통 x1이 들어가고, imm21에는 procedure 시작 instruction이 존재하는 주소를 넣는다.
주로 control을 procedure로 옮기기위해 jal x1, Label로 쓰인다.
(imm21 위치에는 보통 위 conditional branch에서 했듯이 label 값이 옴)
jal은 오직 procedure을 위해 있는 instruction이지만 unconditional jump를 위해 jal x0, Label 식으로 쓰이기도 한다.
(jal/jalr는 unconditional branch가 기본이다. 즉, 위 문법을해야 무조건 점프가 아니라, 바로 위 문법처럼써서 무조건 점프를 함수호출 없이 활용한다는 말이다. 오해하지말기)
3. 해당 procedure에 필요한 storage 공간 할당
register를 우선적으로 사용하는게 제일 좋다. procedure 수행시 사용할 수 있는 register들은 인자 넘겨받는 x10-x17과 x5-x9, x28-x31이 있다. 즉, x5-x31까지 모두 활용할 수 있다.
단, 이전 caller procedure에서 해당 register를 사용하던 중이었을 수 있으니, 사용전 "Stack에" 백업(spill)을 해두고 procedure이 끝날때 restore 해야 한다.
그런데 매 procedure마다 모든 registers를 백업/복원하기엔 소모가 너무 크다. 그래서 아래와 같이 두 종류로 나눠서 본다.
x8-x9, x18-x27은 temporary 값들만 저장하는 register라 callee는 백업없이 막 쓸 수 있다. 단 1번 항목들은 사용하려면 무조건 백업/복원을 해줘야한다. 이렇게 약속함으로써 splling을 줄일 수 있는 것이다.(쓰지도 않은 reg들을 백업/복원하는 소모도 줄일 수 있음)
1)callee가 보존해야하는 registers : x5-x7, x28-x31
2)callee 보존의무없는 registers : x8-x9, x18-x27
(2번 항목에 중요한 정보가 있다면, 그건 caller가 알아서 저장해둬야한다.)
그럼 x5-x31로도 부족하다면?
지역변수가 너무 많거나 너무 커서 registers로 부족하면 그땐 stack에 할당한다.
이렇게 지역변수가 stack에 할당될때"만" fp를 이용한다.(자세한건 아래 'Memory 구조와 Stack' 참고)
[정리]
procedure 내에서 필요한 공간은 register로 활용하는게 좋다. x8-x27은 막 써도 되지만, x5-x7과 x28-x31은 무조건 기존 값을 유지하도록 보장해야하므로 spill/restore을 해야한다.(x10-x17은 파라메터 넘겨받은 것이긴한데, 그걸 보존하진 않으니 그냥 같이 활용하는거지.)
근데 위 registers로도 부족하면 그땐 stack memory 공간에 할당받아서 사용해야한다. 이 경우 fp(x8)도 활용한다.
여기서 spill하거나 지역변수 할당받는 공간은 모두 memory의 stack 영역이다.
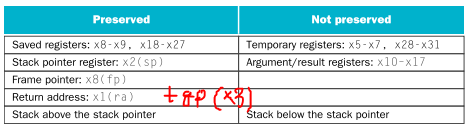
saved register 이외에도 보존해야 하는 값이 들어있는 register들이 있다.
SP, FP, RA, GP인데, 모두 사용할 것이라면 보존해줘야한다.
(예를들어 callee내에서 다른 함수를 호출할거면 이전의 x1은 당연히 stack에 spill해서 보존해줘야함. sp는 fp에 저장해서 보존하는 것이고... gp도 고려해야한다고하네.)
다시한번 말하자면 우측의 값들은 막 써도 된다. 그러니 저장하는건 caller의 몫...
사실 둘의 차이는 보존 의무가 누구에게 있냐는 것 뿐이다. 보존을 할 것인가? 에 대한 답은 "기존 값을 다시 활용할 것인가"에 달렸다. 즉, back up은 했더라도 기존 값을 다시 활용하지 않는다면 굳이 restore할 필요는 없어진다.
4. 작업 수행
procedure의 각종 작업을 수행한다.
5. Calling program이 접근할 수 있는 predefined 위치에 result value를 삽입
보통 x10-x11에 저장해서 return value를 넘겨준다.
이후 spill했던 registers를 다시 restore해준다.
(해당 지점 기준으로 spill했던 registers를 사용하지 않았다면 restore 작업은 필요없다. 메모리 접근은 느리니 줄이는게 좋음.)
6. control을 기존 위치로 반환
- jalr rd, rs1, imm12 (I-type)
jalr instruction은 (1)rd에 PC+4의 값을 저장하고, (2)rs1의 값 + imm12위치로 branch한다.
주로 control을 기존 위치로 다시 옮기기위해 jalr x0, 0(x1)로 쓰인다.
jal에 비해 더 멀리 jump할 수 있는 instruction이다.(rs1의값 + 12비트수 니까..)
함수 반환시에는 jalr x0, 0(x1)으로 x0를 이용해 PC+4 값은 버리고, x1의 값을 이용해 다시 돌아가는 것이다.
(아마 parameter을 stack을 통해 넘겨줬다면 6번과정 수행 후 해당 stack 공간을 없애지 않을까 싶다. 아니면 함수 호출됐을때 없앴을 수도 있고? 뭐 정하기 나름이긴할듯)
지금까지 RISC-V에서의 일반적인 함수 호출 과정을 설명했다.
함수 호출 규약(calling convention)에 따라 procedure이 실행되는 세부사항은 달라질 수 있다.
참고 예시: x86-32 함수 호출 규약
Memory 구조와 Stack

우선 한 프로그램이 메모리에 올라갔을때 구조는 보통 위와 같다.(Linux)
특정 프로그램이 실행되면 그 프로그램이 메모리 위에 올가가게 된다. 그 한 부분을 나타낸 것이다.
한 프로그램은 32bit 컴퓨터 기준 4GB의 메모리를 사용할 수 있다.
프로그램 10개만 돌려도 40기가인데,, 말도 안되는 것 처럼 보이지만, OS가 알아서 잘 처리해주기때문에 그 프로그램의 입장에선 4GB를 사용한다. 위 그림도 한 프로그램이 메모리에 올라가 있는 걸 표현한 것이다.
우선 가장 낮은 부분은 예약돼있다.(목적은 잘 모르겠네)
이후 text segment라는 것이 오는데, 해당 프로그램의 instruction들이 들어간다. 그래서 PC도 보면 저 위치에 있다.
(쉽게말해 우리가 작성한 소스코드가 기계어로 번역된 것. 저게 실행되며 프로그램이 실행된다.)
그 위엔 Static Data 영역이 온다. 말 그대로 C에서의 상수나 static storage class를 가지는 데이터들이 저 곳에 저장된다.
그 위에는 Stack과 Heap이 반대방향으로 자라도록 배치된다. 효율적으로 메모리를 활용한다.
Static data를 다루기 위해 Global Pointer(gp)를 x3으로 사용한다.(이것도 당연 관습인듯)
Heap을 다루기는 쉽지 않다. 메모리를 너무 빨리 해제하면 dangling pointer가 돼버리고, 해제를 까먹거나 늦으면 memory leak이 돼버린다. 그래서 Java에선 이런걸 다 자동으로 관리해준다.
위 memory 공간 중 stack을 자세히 살펴보자.
< Stack >
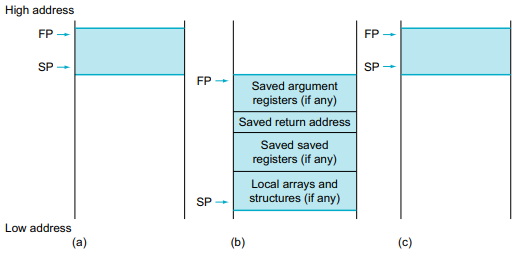
Stack은 역사적인 이유로 낮은 주소 방향으로 자라난다.
SP(Stack Pointer)가 top 위치를 가리키고, FP(Frame Pointer)는 해당 stack 구간의 base 주소를 가리킨다. (x86에서 esp, ebp 역할)
procedure가 호출되면, 이전 procedure의 SP의 값은 FP에 백업된다.(무조건 FP 쓰진 않음, 아래 'FP 필요성' 참고)
x2가 sp의 역할을 하고, x8이 fp의 역할을 한다. x2와 x8 사이 저렇게 procedure의 데이터를 저장하는 곳을 procedure frame 혹은 activation record라 한다.
<FP 필요성?>
FP가 있으면 procedure가 호출될때 SP만 움직이는게 아니라, FP가 이전 SP 주소를 저장하여
(1) 해당 procedure의 바운더리를 설정해줄 수 있다.
만약 FP가 없다고 해보자. 어떤 함수가 호출돼서 stack에 쌓일때마다 SP는 바뀐다. 그럼 Stack내에 할당된 지역변수를 호출하려면 SP의 상대 주소를 활용해야하는데, 매번 그 주소가 바뀌므로 offset이 매번 바뀐다.(procedure 중간에 변수가 선언되고 할당되는 것도 포함되나..?)
특정 함수의 FP를 base 주소로 박아버리면 그런걸 고려할 필요가 없다. 즉 아래와 같은 효과가 있다.
(2) 지역변수 접근의 일관성을 준다.
그래서 지역변수를 쓰는게 아니라면, 예를들어 register를 백업하거나,매개변수를 넘겨줄땐 어차피 SP 기준으로 뺐다가 다시 SP도 원상복구 시키니 굳이 FP를 활용하지 않는다.(그럴땐 오히려 FP 쓰는게 더 낭비임, SP로 다 처리 가능)
(참고로 매번 그랬듯이 stack 메모리에서도 SP를 옮길때 주소 계산은 1byte 단위로 하지만, register bit수에 맞게 word나 dword로 한다. 즉 4의 배수나 8의 배수로 한다.)
> tail call optimization
몇몇 recursion(recursion은 tail call의 한 예이다.)은 iterative 형태로 효율적으로 작성될 수 있다. 함수 재귀호출을 사용하지 않음으로써 overhead를 줄여 최적화하는 것이다.
자세한건 구글에 "tail call optimization" 검색...
leaf procedure과 recursive procedure 코드 예시는 강의자료 Chapter2 후반부 참고
Wide Immediates and Addressing Mode
register에 값을 어떻게 올릴까?
addi를 써봤자 하위 12비트밖에 올리지 못한다.
그러니 register 전체 다 활용해서 값을 작성하고 싶다면 아마 store 종류 instruction으로 메모리에 한 바이트씩 읽어서 register 크기에 맞게 lw나 ld로 읽어서 값을 작성해야할 것이다.
U-type

이때 사용하는 것이 lui(Load Upper Immediate) instruction이다. U-type이다.
이 20비트 immediate 값을 이용해서 31:12까지의 bit를 채우는 것이다.(0번째 비트부터 시작한다 가정)
즉, 32bit register의 남은 부분을 모두 채울 수 있다. 64bit register에 사용하면 좌측 32개 비트는 sign extended된다.
우측 12비트는 0으로 채워진다. 이 남은 12비트는 addi로 채운다.
> 주의
1. lui는 상위 20비트를 지정된 imm 값으로 만들고, 하위 12비트는 0으로 만든다. 즉 딱 상위 20비트에만 로드 되는게 아니라 하위 12비트에는 0을 채워서 로드하는 것(직접 돌려봄). 그러므로 lui로 상위 20비트를 만든 후 addi로 나머지 값을 더해주는게 옳은 순서이다. addi를 하고 lui를 하면 하위 12비트가 0으로 덮어씌워진다.
2. addi로 낮은 자리수 12bits를 채울때 MSB가 1이라면 조심해야한다. addi는 근본적으로 덧셈 연산이기때문이다. 원래 imm값을 register의 값과 더할때 12비트 imm값을 sign extend 시켜서 32비트로 만든 후 덧셈을 진행한다.
따라서 addi로 올리려고하는 낮은 12bits의 MSB가 1이라면 위쪽에 lui로 올려둔 값에 영향을 줄 수 있으니 잘 컨트롤해야한다.
SB-type & UJ-type


각종 branch문이 모두 "SB-type"이다. (beq, blt 등등...)
"UJ-type"에는 jal이 있다. (위에서 말했지만, jalr은 I-type임)
<SB, UJ 공통사항들>
1.
보면 알겠지만, 전체적인 틀은 S-type/U-type과 같은데 imm이 이리저리 쪼개져있는 것만 다르다.
이유는 hardware의 단순화를 위해서이다.(대신 assembler가 하는 일을 좀 늘린다.)
2.
branch이든 jump이든 둘 다 PC-relative addressing을 사용한다.
즉 PC를 기준으로 offset 값을 전달받아 분기를 한다는 것이다. 이 offset 값을 이용해 byte 단위로 점프한다.
주의할 점은, 전달받는 offset은 byte 단위이긴하지만, 막 주면 안되고 instruction byte 수의 배수로 줘야한다.
1) 왜 특정 register를 기준으로하는 상대주소를 쓸까?
절대주소를 쓴다면, jalr을 써도 최대 2^20의 주소까지밖에 표현을 못한다.
즉, 프로그램이 최대 2^20 byte 크기밖에 안된단 소린데 실제 프로그램을 적기엔 너무 작다... 1MB임
그래서 특정 register의 값(32bit) + offset으로 주소를 결정하도록 해서 2^32 크기만큼 표현할 수 있게 하는 것이다.
(2^20이나 2^32나 그게 그거 아닌가 싶은데 차이 엄청남)
2) 그럼 왜 PC를 기준 register로 삼는 것일까?
branch를 사용하는 if나 loop가 현재 실행중인 instruction에서 PC에서 멀리떨어져있지 않은 곳으로 가는 경우가 많다.
실제 SEPC benchmark를 봐도 조건 branch의 절반정도가 16개 인스트럭션보다 적게 branch한다.
그래서 PC가 가장 이상적인 선택지이다.
branch로는 플마2^10개 instructions 점프할 수 있고, jump로는 플마2^18개 instructions 점프할 수 있다.
※주의※
활용 가능 비트 수와 jump 가능한 instruction 수를 헷갈리지 말자.
활용 가능한 비트 수는 점프할 offset이다. 이 offset 1당 1byte를 점프한단 소린데, 보통 instruction은 4byte임을 기억해야한다.
instruction은 보통 하나에 4bytes다. 그러니까 PC는 항상 4씩 증가하는 것이다. 우리가 PC-relavent addressing을 할때도 4의 배수를 써줘야한다.
점프 가능한 byte만 보자면 2^13, 2^21이 맞겠지만, 부호 비트를 빼고 instruction하나에 4바이트인 점을 고려하면 플마 2^10과 플마 2^18 instruction만큼 점프할 수 있는게 된다.
instruction 2byte 짜리를 지원안하고 4byte로 통일했으면 비트 2개를 벌 수 있다.
3.
SB-type은 쪼개진 imm을 합치면 총 12비트, UJ-type은 총 20비트가 나온다.
하지만 실제로 imm 나타내는데 활용하는 비트수는 각각 13개와 21개이다. 즉 총 1비트씩 더 사용한다는 것이다.
RISC-V 설계자들은 2byte instruction을 지원할 경우도 생각해서 branch나 jump가 2(byte) 단위로 이뤄지도록 했다.(hw)
2(byte) 단위면 주소는 마지막 자리가 무조건 이진수로 0이다. 그러므로 이는 굳이 encoding할 필요가 없는 정보이니 LSB는 항상 0이라고 가정하고 LSB 제외 그 위 bit들만 imm에 들어가는 것이다.(IEEE754에서 최상위 1로 하는거랑 비슷)
<더 멀리 JUMP하기>
branch나 jump의 능력 한계보다 더 멀리 가야할 수도 있다.
1. 조금 더 멀리
//beq x10, x0, L1 //아래 코드는 이와 같다. 단, 아래가 더 멀리 갈 수 있음
bne x10, x0, L2
jal x0, L1
L2:일반 branch가 아닌 jal의 힘을 빌려 최대 2^20로 점프 능력을 향상시킨다.
2. 훨씬 더 멀리
//beq x10, x0, L1 //L1의 상위 20비트: L1_U20, 하위 12비트: L1_L12
lui x9, L1_U20
addi x9, x9, L1_L12 //위에서 언급했듯이 L1_L12의 MSB가 1인지 보긴해야 됨
bne x10, x0, L2
jalr x0, 0(x9)
L2:register 값을 base로 활용하는 jalr이 jal보다 멀리 나간다.
그래서 lui를 활용해 특정 레지스터(여기선 x9)에 값을 저장하고, jalr로 더 멀리 점프한다.
imm영역 bit 수를 기준으로 정리하자면,
branchs: 12bit + 1
jal: 20bit + 1
jalr: 32bit (register 값 기준으로 offset 계산하니까 32bits 활용)
<Addressing Mode>

Addressing mode란 operand로 필요한 data를 어디에 위치시키는지에 대한 것이다.
1. Immediate addressing : constant가 instruction 내부에 존재 ex)addi
2. Register addressing : operand가 register 자체 ex)add
3. Base(displacement) addressing : operand는 memory에 있고, 그 주소는 register와 constant의 합 ex)sd,ld,sw,...
4. PC-relative addressing : branch address가 PC와 constant의 합 ex)jal, beq
(addi는 2번도 해당되는게 아닌가? 생각했는데,, 그렇게 따지면 2번에 해당 안되는 instruction이 없다. 대표적인거 특징적인거 기준으로 보는 듯...? 아니면 진짜로 전부다 2번은 passive로 해당될 수도 있고...?)
Fallacies & Pitfalls
Fallacies(오류)
1. More powerful instructions mean higher performance.
: 특정 연산을 수행할때 오히려 간단한 버젼을 활용하는게 더 빠르다는 반례가 있다.(책 p.170 참고)
2. Write in assembly language to obtain the highest performance.
: 엄청 예전에야 뭐 그랬을 수도 있지만, compiler가 발전한 요즘은 아니다. 정교한 최적화 기술이 반영된 compiler로 assembly를 작성하는게, 직접 바로 assembly를 작성하는 것보다 오히려 더 빠르다. 그래서 C에서 register로 선언하는 것도 요즘은 의미없는 것이다. 만약 정말 잘 짜서 compiler가 번역한 것보다 더 빠르다고 할지라도 그걸 작성하는데 쏟는 시간과 유지보수하는데 드는 노력에 비하면... 그래서 그냥 더 고수준 언어로 코드를 쓰는게, 나중에 다른 machine이 나와도 그에 맞는 compiler만 사용하면 되니 portability도 있고, 유지 보수도 쉽다.
3. The importance of commercial binary compatibility means successful instruction sets don't change.
: x86을 보면 답이 나온다. 매우 성공한 ISA이지만 instructions 수가 1978년 100여개에서 약 40년 후인 2017년에 1400여개까지 증가했다.
Pitfalls(위험)
1. Forgetting that sequential word addresses in machines with byte addressing do not differ by one.
: C에서야 type따라 포인터연산 알아서 해주지만, assembly를 쓸거면 다 신경써야한다.
2. Using a pointer to an automatic variable outside its defining procedure.
정리
Stored Program의 두가지 주요 원리
1. the use of instructions that are indistinguishable from numbers.
2. the use of alterable memory for programs.
(위 두가지를 기반으로 지금의 복잡한 AI 기술 등이 나올 수 있었음)
Instruction sets을 만들때 적용된 원리
1. Simplicity favors regularity.
: 모든 instruction이 같은 size이고, arithmetic 연산시 register operands만 사용하도록 함. 모든 instruction format에서 register의 위치를 고정함.
2. Smaller is faster.
: 속도도 중요한 요소이니 딱 32개의 register를 갖도록 함.(위에서도 말했지만, 1개정도 더 많다고 느려지진 않을 수도 있다. 그러나 instruction format의 비트 수 제한도 있고, 프로그래머/디자이너 사이 밸런스를 맞춘 것이기도 하다.)
3. Good design demands good compromises.
: 큰 address와 constant를 지원하고자하는 것과 모든 instruction의 길이를 통일하고자 하는 것(하나의 instruction format만 갖고자 하는 것)을, RISC-V는 모든 instructions이 같은 길이를 갖도록 하고 대신 서로 다른 format을 갖도록 함으로써 절충한다.
(format별로 다양하게 변형되며 address 길이도 다양하게 지원하고... etc)
정해진 type이란 없다. data는 모두 숫자일 뿐이고, 그 숫자를 해석하는 program에 따라 그 숫자가 무엇인지 결정될 뿐이다.
common case fast의 한 예
: conditional branch에선 PC-relative addressing을 사용하고, 더 큰 숫자 operand를 위해선 immediate addressing을 사용
(PC에서 가까운 곳으로 점프하는 conditional branch는 PC를 기준으로 점프하는게 당연 더 빠르다... 방식을 통일시키면 한쪽이 손해를 봄)
abstract의 한 예
: assembly는 machine instruction과 1:1 대응이지만 모두 그런건 아니다. pseudo instructions은 그에 딱 맞는 1:1 대응이 존재하지 않는다. pseudo instructions 또한 기계어 단에서는 알 수 없도록, assembly쪽에서 처리하도록 abstract된 것이다.
추가...
pointer와 array를 다르게 컴파일하던 예전 컴파일러는 pointer로 배열 연산을 하는게 좀 더 빨랐지만, 최근 컴파일러들은 알아서 잘 해주니 차이가 없다.
Java에서의 byte code는 instruction인 셈이다. JVM이라는 ISA가 이를 구동한다.
Java는 interpreter 기능을 하므로, translator 기능을 하는 C/C++보다 느린 것이다. 물론 자바 코드도 instruction으로 바로 컴파일 되기도 한다.
최근 Java는 실행속도 향상을 위해 실행될때마다 가장 자주 쓰이는 함수 등을 찾아서 해당 부분을 실제 instruction으로 변환한다. 그래서 다음 실행때는 이 변환된 코드를 활용해 실행함으로써 실행 속도를 높이는 것이다.(JIT 라고 함)
(나중에 자바 제대로 공부할때 여기 자바 나오는 부분들 한번 쭉 보면 좋을 듯)
자바는 시대가 변하며 메모리가 여유있어지니까 machine independency를 높인 것. C는 같은 소스코드여도 컴파일러마다 조금씩 다르게 컴파일 될 수 있고, machine마다 OS마다 다른 컴파일러를 사용해야 하지만, Java는 JVM 위에서는 어떤 java source code도 똑같이 돌아간다..고 하네
(chap1에 있던 내용이긴한데) python 같은 놈들도 같은 source 코드만 딱 놓고보면 C보다 당연히 느리지만, python의 최적화된 라이브러리 등을 활용하면 같은 기능만 하도록 간단하게 짠 python 코드보단 꽤 빠르다.
RISC-V spec을 보다보면 뒤에 I나 M이나 어떤 알파벳이 붙는데, 이건 instructions을 분류한 것이다.
가장 기본적인건 I(base architecture)이고 나머지는 extensions라고 한다.
아마 extensions은 하드웨어 필요에 따라 지원하는 놈도 있고 안하는 놈도있고 하드웨어마다 다르게 지원할 수 있도록 한듯..?
Q. 같은 ISA를 따르는 CPU 두개가 있는데 그 위에 서로 다른 OS가 설치된 A와 B 컴퓨터가 있다고 해보자. 특정 C source code를 A에서 컴파일하면 어떤 sequence of machine instructions으로 컴파일될텐데, 그럼 이 sequence of machine instructions(실행파일)를 B로 그대로 옮겨서 실행했을 때 B에서도 그대로 잘 실행 될까?
A. 결국 같은 CPU에 같은 machine instruction이기 때문에 OS가 달라도 아무 이상 없이 실행될 것 같다. 하지만 대부분 프로그램은 OS specific library나 system call 같은 것을 사용하기 때문에 OS가 다르면 제대로 실행되지 않을 수 있다는 것은 알고 있어야한다. (OS specific library라 하면 뭐 당연히 stdlib.h나 stdio.h 같은 표준 라이브러리가 아닌 pthread 같은 것을 말함)
물론 만약 그런걸 전혀 사용하지 않은 C source code를 컴파일했다면, OS가 달라도 같은 CPU면 stable하게 실행시킬 수 있다.
'수업 > Computer Architecture' 카테고리의 다른 글
| [Computer Architecture] Processor - 1 (0) | 2022.11.08 |
|---|---|
| [Computer Architecture] Memory Hierarchy (0) | 2022.10.20 |
| [Computer Architecture] Arithmetic for Computers(2) (2) | 2022.10.18 |
| [Computer Architecture] Arithmetic for Computers(1) (0) | 2022.10.13 |
| Introduction (3) | 2022.09.13 |