아래 사항들을 배운다.
1. Implementation of subset of core instructions
2. ISA가 구현에 끼치는 영향
3. 구현 방식에 따라 CPI나 clock rate에 끼치는 영향
(여기서 배우는 기본 개념들은 서버부터 임베디드 processor까지 모든 컴퓨터에 적용된다.)
> Overview of Implementation
모든 instructions은 아래 두가지 공통 사항들을 출발점으로 진행된다.
1. PC에 저장된 주소가 가리키는 곳에 저장된 instruction을 memory에 올린다.
2. 양식에 맞게 register 1개 혹은 2개의 값을 읽어온다.
이후 진행 과정은 instructions 종류에 따라 다르게 진행된다.
하지만 RISC-V의 simplicity와 regularity 덕분에 전체적으로 비슷한 부분 좀 있다.
예를들어 모든 instructions은 위 과정 진행 이후 ALU라는 H/W를 이용해 다음 과정을 진행한다.
ALU를 사용한다는 점은 같지만, 사용 목적은 아래와 같이 각각 다르다.
memory-reference inst. : for address calculation
arithemetic-logical inst. : for operation execution
conditional branch inst. : for branch target address (+책에선 for equality test 용도로 있다고 함, 회로보면 머 둘다 맞는듯)
> Logic Design Basics
가장 기본 단위는 logic gates이다. ex) and, or, ...
더 밑으로 내려갈 수도 있겠지만 일단 logic gates를 가장 밑단으로 본다면, and or 등의 logic gates가 모여서 특정 기능을 하는 회로를 구성한다.
이렇게 만들어지는 회로는 아래와 같이 두가지로 분류된다.
1. Combinational Element
- 내부 storage가 존재하지 않는다.
- 같은 input이라면 무조건 같은 output이 나온다.
- ex) ALU
- (어떻게 보면 ALU의 더하기 같은 것도 더하기를 실제로 한다기보다는 더하기 결과가 나오도록 input과 output이 mapping시켜 회로를 짠 것이다.)
2. State(Sequential) Element
- 내부 storage가 존재한다.
- 같은 input이여도 내부에 저장된 값에 따라 output이 다르다. (내부 저장 값도 사실상 input으로 들어가기때문)
- output이 (1)현재 input과 (2)이전의 input 둘 다의 영향을 받는다.
- ex) register
- 최소 두개의 input과 하나의 output을 가진다. input은 (1)작성할 data와 (2)data가 작성될 시점을 정해주는 clock을 받는다. output은 이전 clock이 튈때 저장하는 값이 튀어나온다.
전산분야에서 state라는 말은 "특정 순간의 memory 안의 값"이라는 의미?를 가지고 있다.
state라는 말이 붙은 이유도 그런 맥락이다. 내부 storage가 특정 순간의 값을 다음 clock까지 유지한다.
실제로 파워선을 뽑아버리더라도 state element에선 뽑기전의 값을 저장하고 있다.(고 책에서 말하네)
sequential(순차적인)이라고도 하는 이유는 output이 input과 internal state에 의해 결정되기 때문이다.
> Clocking Methodology
SC에 read/write하는 timing은 제어돼야한다. 아무때나 읽고 쓸 수 있다면 동시에 읽고 쓰는 경우가 생길 수도 있고, 그래버리면 output은 예측불가가 돼버린다.
(writing과 reading이 동시에 발생하면, 예전값을 읽어오는지 새로 쓰여지는 값을 읽어오는지 아니면 둘이 섞인 값을 읽어오는지 알 수가 없다.)
(writing들만 동시에발생? 같은건 안되니 생각할 필요 없을듯, register하나에 write 회선 두개가 꼽힌다는게.. 말이 안되는듯)
그래서 보통 clock 신호를 기준으로 read/write를 수행한다.
clocking methodology를 이용해 H/W가 predictable하게 만드는 것이다.
clock 신호를 기준으로 하는 방식에는 (1)level-sensitive와 (2)edge-sensitive가 있다.
(위 두 방식에 각각 2가지씩해서 총 4가지임.. positive/negative/posedge/negedge)
edge에 read/write를 맞추는 것은 Edge-triggerd Clocking 이라고 한다. 그리고 책과 ppt에선 얘를 사용한다.
0→1로 변하는 positive edge을 기준으로하든, 1→0으로 변하는 negative edge을 기준으로하든 상관은 없다.
이렇게 clock을 SC의 input으로 같이 꼽아서 clock의 edge마다 SC의 값이 update되도록 한다.
State elements에 clock이 꼽혀있는건 너무 당연해서 종종 생략되기도 한다.
만약 매 clock마다 State element의 값이 바뀌는게 아니도록 만들고 싶다면 control signal이 추가로 필요하다.
만약 control 신호도 있다면, State element의 값은 (1)write control이 켜지고, (2)clock edge가 발생할때, 둘 다 만족해야 값이 update 된다.
asserted란 신호가 켜졌다(1)는 의미이고, deasserted란 신호가 꺼졌다(0)는 의미이다.
우리가 보는 대부분의 회로는 아래와 같이 구성된다.
값을 저장할 수 있는 SC에서 값을 꺼내와 CC를 거쳐 다른 SC에 값을 저장한다.

여기서 중요한 점은 Combinational logic의 과정은 1 clock 안에 끝나야한다.(stable 해야한다.)
CC가 복잡해서 1clock 안에 연산이 끝나지 않으면, 두번째 clock이 튈때는 뒤의 state element에 이상한 값이 들어갈 수가 있다. 아직 combinational logic에서 계산이 진행중일때에 state element2의 문이 열려버리면 당연히 제대로 된 값이 들어가지 못한다.
그래서 Optimal clock cycle 길이는 combinational logic에 의해 결정된다.
(아니면 반대로, 정해진 clock cycle 길이 내에 모든 CC가 끝나도록 할 수도 있을 것 같다..)
(교수님께서 설명을 약간 후자 뉘앙스로 하셨음,, 1 cycle 안에 끝나게 해야한다고, 아니면 clock cycle을 늘려야하는데 이는 성능에 안좋다고.. 그냥 서로 영향 받는다는걸 알고 있으면 되지않을까 싶긴하네)
edge-triggered 방식을 사용한다면 아래와 같은 순환하여 한 clock에 read/write를 동시에 진행하는 경우에도 잘 작동한다.

state element에 문이 있다고 생각하면 됨. 그리고 그 문은 clock이 튈때 잠깐 열림.
Combinational logic은 중간에 뭔가를 저장하거나 가로막지않고 쭉 흘러보낸다.
"clock이 튈때" state element 바로 뒤의 combinational logic을 거쳐와 대기중인 값이 state element를 통해갈때 다시 문이 닫히는 것이다. 위에 화살표 2개 각각 다른 값을 지나고 있다고 보면 된다.
(state element는 값을 저장하는데 그 저장되어있는 값이 출력으로도 항상 나온다.)
Building Datapath
몇가지 주요 RISC-V Instructions을 수행하는 Datapath를 공부해보자.
R-type instructions, ld, sd, branch instructions에 대해 알아본다.
전체 Datapath를 보기전에, 우선 특정 기능을 수행하는 기본 회로 요소들과 그걸로 수행할 수 있는 instructions을 개별적으로 알아보자.
아래에 나오는 Datapath elements는 모두 위에서 배운 logic gate 등으로 구성된 회로이다.
그걸 우리는 세부사항을 그냥 박스로 추상화함으로써 회로가 하는 기능에 집중해서 본다.
> 기본 Unit
위에서 봤던건데, 다시 한번 보자. 모든 instructions은 다음 과정을 거친다고했다.
1. Fetching the instructions
2. Read one or two registers
Datapath를 설계하기 위해 가장 기본인 이놈들을 지원해주는 Datapath elements를 보자.
(교수님께서 추가로 설명해주신 내용)
아래에 나오는 Unit들 중에 PC를 제외한 모든 Unit은 combinational element로 간주된다.
뭐 내부적으로 결국은 state element랑 연결되고 하니까 엄밀히 말하자면 Instruction memory, data memory, register file 모두 state element는 맞다.
하지만 아래 이유로 한 clock cycle에 동작한다고 봐도 무방하다.(가볍게 comb.라고 생각해도 무방(?)하다.)
Instruction memory: 얘는 항상 read만 하는 메모리이다. 따라서 write되는 시점을 동기화 할 필요가 없으므로 아무때나 입력으로 들어오는 주소의 메모리 값을 읽어내기만 하면 되므로 comb.로 취급한다.(책에도 있는 내용)
Register file: rs1, rs2를 읽는 경우는 instruction memory와 같이 주어진 regsiter 번호의 내용을 그냥 읽어내기만 하면 되므로 clock에 동기화에 의존할 필요가 없다. 다만, rd에 write를 하는 경우가 있는데 이 경우는 현재 cycle에서는 instruction (i1이라고 부른다면)의 모든 처리가 끝나는 시점에서 write register 번호와 write 할 data가 regsiter file의 write port들에 준비만 되는 것이며 실제 값이 resiter file 내부의 특정 register에 쓰여지는 것은 그 다음 clock이 튈 때 이루어지는 것이다. 이 clock이 튀는 동시에 PC는 새로운 instruction주소로 업데이트 되며 이 새 inst 주소가 사용되기 (즉 instruction i2) 시작하는 동시에 register에 값이 쓰여지는 것이므로, i2가 register file을 접근하는 시점에서는 이미 i1이 만들어낸 새 rd register 값이 register file내의 rd에 쓰여진 상태이다. 따라서 i2 동작에서 잘못된 register 값이 사용될 가능성은 없다.
Data memory: read하는 경우는 위와 동일한 논리라고 생각하면 된다. Write의 경우도 새로운 값이 실제 써지는 타이밍은 현재 cycle이 끝나고 다음 clock이 튀는 시점이다.
● Instruction Memory

Instructions이 담겨있는 unit이다. instructions이 담겨있는 실제 memory는 아니고 instructions이 담겨있는 외부 memory와 연결돼있어서 값을 가져올 수 있는 interface로 생각하면 된다. (실제로 L1_i cache같은게 여기에 해당한다.)
그림에 보이듯이 instruction의 주소를 넘겨주면 해당 주소의 instructions을(즉 data를) output으로 보내는 역할을 하는 unit이다.
엄밀히 얘는 state element이긴하지만 combinational logic처럼 대해진다. read only라서 writing이 동시에 발생할 위험같은 것도 없고, 그냥 읽는대로 내보낸다.
● Program Counter

현재 수행하는 instructions의 주소값을 갖는다.
register이므로 state element이다. 그림엔 표현이 안됐지만, Clock 신호와도 연결돼있다.
다른 (엄밀히 말해서) state elements인 reg File이나 I Mem, D Mem 같은 애들은 read/write 신호가 다 있거나, 없더라도 없는 이유가 있다.
PC도 마찬가지로 아무 신호가 없는 이유를 설명해보자면, 그냥 매 clock마다 read/write가 무조건 일어나기 때문이다.
● ALU

Chapter 3에서도 본 ALU이다. 연산 신호로 4비트가 들어가므로, 신호에 따라 다양한 연산을 수행할 수 있다.
(2^4 == 16?? 근데 실제로 16개나 있는지는...)
두 operands의 (1)연산 결과와 (2)연산 결과가 0인지를 출력한다.
(얘는 당연히 clock이 튀든 말든 계속 데이터가 흘러나가는 combinational element이다.)
● Fetching the Instructions
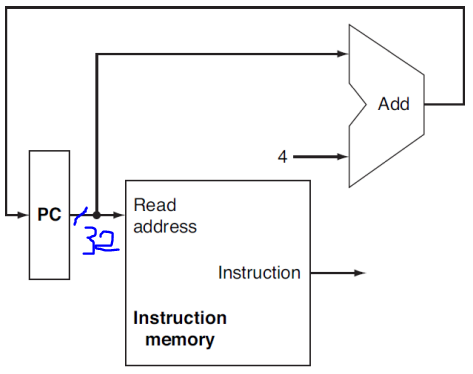
위에서 배운 unit들을 종합해서, (1)다음 instruction을 가져오고, (2)PC 값을 그 다음 instructions 주소로 업데이트하는 회로를 만든 것이다.
ALU는 "Add" 역할로 고정돼있다. 또 한 operands도 "4"로 값이 고정돼있다. 여기서 Add는 아예 +4를 하는 역할로 고정된? 특수화된? 놈인 것 같다, zero 신호도 따로 없는 듯 하고...
(까먹을까봐 다시 말하자면, instruction이라는 데이터 하나의 크기는 32bit로 고정이었다. opcode~funct7까지 32비트안에 다 넣었음)
각 회로 선은, 1줄로 나와있어서 딱 보이진않지만, 여기선 PC의 크기를 32비트로 보고 있기때문에 32-bit이다.
(다른 선도 다 따져가며 보자, 여기선 뭐 IM에서 나오는 선이나 "4"가 꼽혀있는 회로도 모두 32-bit인데, 다른데선 다를 수도 있다.)
1. Fetching the instructions
2. Read one or two registers
이제 위 공통 부분 두가지 중 첫번째를 하는 회로를 알아봤으니, 두번째로 register의 값을 읽어오고 register에 값을 작성하는 unit에 대해 알아보자.
● Register file

우리가 배운 x0~x31까지 32개의 registers가 여기 모여있다고 보면 된다. 이를 register file이라고 한다.
input으로는 5-bit를 준다. 총 32개니까 5-bit 신호를 이용해 각 register를 0~31번 번호로 구분하여 지정하는 것이다.
그럼 output으로는 input으로 들어온 register 번호대로 값을 읽어서 해당 registers의 Data를 내보내 준다.
혹은 input으로 작성할 Data를 줘서 register에 data를 작성할 수도 있다. 단 이때는 RegWrite 신호가 asserted여야한다.
RegWrite 신호가 없다면 write reg/data로 들어오는 값에 의해 (그 값이 의미없어도) 해당 값으로 계속 기존 값을 덮어씌우게된다. 따라서 이 신호는 필요하다.
Read는 그냥 input 반영해서 계속 나오기때문에 별도 control 신호가 없다. write는 control에 따라 작동한다.
Combinational element로 간주된다.
> R-type Instructions(arithmetic-logical instructions) 지원 Unit
(R-type은 memory를 접근/사용하지 않고, CPU내에서 모두 처리된다.)

회로의 앞부분은 앞에서 봤던 instruction fetching하는 부분과 register file에서 register 값을 읽어오는 것이다.
더 추가된 것은 사실상 뒤에 ALU 밖에 없다. ALU에서 두 data가 연산을 한 뒤 결과가 다시 register file로 들어가서 write된다. 그림에 표시는 안돼있는데 write신호가 켜져있어야한다.
ALU의 Zero 신호같은건 여기선 사용이 안되긴하지만 회로가 어딘가에 연결이 돼있긴하다. 실제로 (쓰레기) 값도 흘러나올 것이다. 애초에 해당 부분에서 사용하지 않으면 이렇게 선 표시를 안하기도 한다.
이런 값들은 우리가 수행하는 instructions에서 쓰이지 않도록 control을 mux나 연산을 잘 통제해줘야한다.
> Load/Store Instructions 지원 Unit
● Data Memory Unit

Data가 담겨있는 unit이다. (instructions에서처럼) 실제 memory는 아니고 data가 담겨있는 외부 memory와 연결돼있어서 값을 가져올 수 있는 interface로 생각하면 된다. (실제로 L1_d cache같은게 여기에 해당한다.)
combinational element로 간주된다.
Address로 메모리 주소를 넘겨주면, 쓸지 말지 신호가 하나만 켜지거나 하나도 안켜진다. 둘다 켜지는 경우는 없다.
쓰는 것이라면 write data input을 활용해 해당 address에 값을 작성하고,
읽는 것이라면 `Read data`로 해당 주소에 저장된 값을 내보내준다.
register file과 달리 read 신호도 추가됐다.
register file은 read에 의미없는 값이 들어와도 그냥 read 해버려서 흘려보내도 상관이 없었다.
하지만 memory는 invalid한 주소를 읽는 것이 문제가 될 수 있기때문에 read를 필요할때만 써야한다.
write 신호가 있는 이유는 register file에 write 신호가 있는 이유와 같다.(고 볼 수 있을거임. 이건내생각)
● Immediate Generation Unit (ImmGen)

immgen이라는 unit으로, 그림에 나와있다싶이 32-bit input을 64-bit으로 sign extension시켜준다.
RISC-V에서 offset으로 사용되는 데이터는 32-bit instructions 공간 중 12-bit 정도만 들어갔었다. 이를 base-address(or PC-address)와 더해주기 위해선 bit수를 맞춰줘야한다.
그래서 이 unit은 정확히 말하자면 32-bit input 중에서 immediate값(즉, offset값)에 해당하는 12-bit 데이터만 뽑아낸 뒤, 그 놈들 만을 sign extension 시키는 역할을 한다.
참고로 immediate 값의 위치는 흩어져 있을 수도 있고 instruction type에 따라 정확한 위치가 다를 수 있기때문에 특정 자릿수 값만 받아오진 못하고, 32-bit instruction 값을 모두 받아와서 opcode (등)을 통해 imm 위치를 파악해서 계산해주는 것이다.
● 최종

배운 것들을 합쳐서 memory에 접근해서 load/store을 수행하는 회로를 그렸다.
위 회로는 load에 집중해서 사용하지 않는 놈들을 초록색으로 표시했다.(Read data2도 초록색임)
load를 하려면 일단 register의 값과 offset을 더해야한다. 그래서 offset을 sign-extend시켜서 ALU에서 더해주고, 그걸 memory에 접근하는 주소로 사용한다. 이후 memory에서 데이터를 가져와 register에 write하는 과정이다.

이건 store 버전이다. load/store 모두 회로는 같다. 어떤 데이터를 사용하냐가 다르다.
chapter2에서도 봤듯이, load에서처럼 store에서도 Read register1로 보내준 값을 base address로 사용해서 계산한다. base address는 어떤 경우든 다 저 회선으로 보냄으로써 H/W 복잡도를 줄인다.
그 다음으로 두번째 register의 값을 읽어와서 offset과 덧셈을 한 값을 address로 사용해 그곳에 작성해주는 과정으로 진행된다.
> Branch Instructions 지원 Unit

memory 접근하는 회로랑 sign-extension을 하는 것까진 load/store과 같다. 차이는 branch는 PC를 기준으로 하므로 instruction fetching하는 부분에 연결이 돼야한다는 것이다. 그리고 1-bit shift-left도 해줘야한다. 왜냐하면 chapter2에서 봤듯이, PC-relative addressing을 사용하는 경우엔 끝에 1-bit "0"이 있다고 가정하고 instruction을 저장했었기때문에, 다시 PC와 더해주려면 없앴던 0을 추가해줘야 한다.
branch 조건이 참이면 branch is taken이라고 하고, 아니면 branch is not taken이라고 한다.
ALU가 두개가 쓰인다. `beq rs1, rs2, Lable`이라면,,,
(1) rs1과 rs2를 비교할때 빼기 연산을 위해 ALU를 쓰고, zero signal을 보고 같은지 판단한다.
(2) PC와 offset을 더하기 위해 ALU를 사용한다.
branch문을 처리할때는, IMMGEN을 통과해 64비트로 sign extened 된 immediate field는 위에서 shift left 1비트돼서
32비트만 Adder로 들어가서 PC와 더해진다.
하지만, store나 load에선 이 extend된 값을 register 내의 값과 더하기때문에 그냥 64비트 그대로 ALU로 들어간다.
Single Datapath (for R-type, ld, sd, branch)
single datapath란 1 cycle에 1 instructions을 수행하는 datapath를 말한다.
위에서 배운 회로들을 조합해서 R-type, ld, sd, branch를 지원하는 회로를 만들어 보자.
각 회로들이 공통 부분이 많기때문에 아래 Mux라는 회로를 이용해서 합치면 된다.
Multiplexer
S로 들어오는 신호에 따라 I0와 I1 중에 골라 출력한다.
이를 이용해 instructions에 따라 S를 다르게 줘서 흐름을 변경해가며 같은 회로로 여러 instructions을 실행할 수 있다.

> Single Datapath
single datapath가 되려면 한 cycle에 모든 instructions이 수행돼야한다. 따라서...
1. instruction 수행 중에 datapath resource가 두번이상 쓰일 수 없다. 하나를 두번 이상 쓰이려면 클럭이 두번이상 튀어야함.
2. 그러니 우리는 data와 instructions을 다루는 메모리를 각각 나눈 것이다.
아래는 mux와 control을 이용해 다양한 instructions 실행 회로를 엮은 것이다.
아래 Datapath는 1 cycle에 1 instruction을 수행한다.
(위에서 말했지만 state element는 PC 뿐이라고 가정(?)하기때문에 clock이 한 3번 튀어야 아래 회로가 한번 도는게 아닌가 하는 고민은 하지말자.)

파란색으로 표시된 놈들이 control 신호를 주는 combinational element라고 보면 된다.
opcode가 들어오면 그거에 따라 바로바로 control 신호를 준다.
(단, branch 신호는는 and연산도 하고 해야해서 다른 신호에 비해 좀 더 기다려야한다.)
(위 그림이 어떻게 보면 초반에 말했던 state element 두개 사이에 comb element가 있는 그런 꼴이네)
위 그림에서 우리가 아직 제대로 못본 Control 관련된 부분과 instruction data를 넣어주는 부분이 나와있다.
하나씩 자세히 살펴보자.
> ALU Control Unit
위 회로 아래쪽에 ALU control이라고 ALU에게 주는 컨트롤 신호를 전담하는 놈이 있다.
이렇게 main control에서 ALU 전담 control로 mian에서 만든 신호를 보내고, 거기서 다시 실제 ALU control signal을 내보내는 것을 multiple levels of control이라고한다.
이렇게 따로 떼어냈을때 장점은 다음과 같다.
1. main control unit의 size를 줄이고
2. control unit의 latency를 줄일 수"도" 있다
는 장점이 있다.
main control에선 opcode만 보고 간단하게 1차적으로 ALUOp를 내주는 것이고, ALU control Unit에서 funct3과 funct7을 추가적으로 보고 확실한 ALU 신호를 준다.
Input : (Control로부터)ALUOp 2-bit 신호, funct3, funct7
Output : ALU control code 4-bit

ALU는 총 세개가 있지만, 윗쪽 두개는 용도가 고정돼있어서 아래 ALU에만 Control을 주며 용도에 따라 사용한다.
1. R-type일때 → 정확한 instruction에 따라 네가지 다 활용
2. ld, sd일때 → base+offset을 더하기위해 add로 사용
3. branch일때 → 조건 test를 위해 subtract로 사용
아래는 Instructions 종류에 따른 ALUOp 값과 funct7, funct3 값이다. 그리고 각 input에 해당하는 OUTPUT이 가장 우측에 나와있다.
x로 표시된 애들은 아무 값이 와도 상관없다는 의미로, don't care terms라고 한다.

위 표를 통해 아래와 같은 truth table을 그릴 수 있다. ld, sd는 input과 output이 같으니 합쳐서 볼 수 있다.
(그래서 총 6가지 경우로 줄어듦.)
그리고 (여기선) ALUOp에 "11"인 경우는 없기 때문에 "10"이나 "01"대신 "1X"나 "X1"로 적어도 상관없다.

이제 위 기능을 하는 회로를 만들때는, 이런 truth table을 최적화 시켜준 뒤 input에 해당하는 값들에 대해 그것에 해당하는 output을 어떻게 출력하는지 하나씩 보며 매핑시켜주면 된다.(식을 세우기도 하고.. 디테일한건 패스)
눈 여겨볼게 있는데, funct7을 보면 왼쪽에서 두번째 자리(I[30])만 딱 한번 다르다.
그러니 input 모든 경우인 2^12를 싹 다 output에 하나하나 매핑시킬 필요가 없다. funct7은 딱 저 자리만 보면 된다.
즉, 실제로 ALU Control Unit의 output을 알기 위해 봐야할 것은 ALUOp 2-bit, I[30], I[14-12] 까지 총 6-bit 뿐이다.
★
위에서부터 하나씩 보면, 우선 ld/sd인 경우 ALUOp가 "00"이다. 이 경우 funct는 확인할 필요 없이 곧바로 0010(add)을 출력한다.
beq도 마찬가지다. ALUOp가 "01"이라면 (혹은 그냥 뒷자리가 1이라면), funct 확인하지않고 곧바로 0110(sub)을 출력한다.
마지막 R-type 친구들은 funct 값을 봐야 구분이 된다. and/or는 funct3으로 구분이 되고, add/sub는 funct3이 같지만 I[30]이 달라서 구분된다. 각각에 해당하는 연산을 지원하도록 출력한다.
정리하자면 ld,sd와 beq는 ALUOp 에서부터 구분이 되지만 R-type 놈들은 funct까지봐야지 확실하게 ALU control 신호를 알 수 있다.
> Instructions 분배

Ch2에서 봤듯이 이렇게 element의 위치는 type이 달라도 고정되는게 많았다. rd,rs1,rs2 모두 위치는 항상 고정된다,,,
base address 값을 담는 용도의 register 위치를 항상 rs1로 고정시키기 때문에, ld 어셈블리어는 "ld rd, rs1, 0(rs2)" 였던 반면에 sd는 "sd rd, rs2, 0(rs1)" 으로 둘은 assembly 포맷에서 순서 다르게 배치됐다.
결국 그 덕에 회로 연결이 간단해져서 H/W를 비교적 간단하게 만들 수 있다.
만약 type별로 넣어야하는 게 다르다면, mux로 type마다 다르게 흘러가게 처리하는 등 추가 작업이 필요할 것이다.
특히 opcode 위치와 크기는 항상 고정이었다. opcode는 instruction decoding시에 가장 처음으로 봐야하는 정보이다. 이걸 봐야 나머지 부분을 해석할 수 있는데, 이게 매번 다르다면 매우 골치아플 것이다.
그래서 아래 그림과 같이 (위 표 기준으로) rd 위치(I[11-7])는 항상 Write register로 들어가게 하고, rs1(I[19-15])은 Read reg1로, rs2(I[24-20])는 Read reg2로 들어가게 한다.
ImmGen으론 32비트 모두 넣어야한다. 그 이유는 immediate 값의 위치는 고정이 아니라 모두 받아서 type별로 immediate 값을 다르게 뽑아내야하기 때문이다.
또 위에서 봤듯이 ALU Control Unit으로는 I[30], I[14-12]를 넣어준다. (ALUOp는 Main control에서 들어옴)
아래 그림엔 없는데, I[6-0]인 opcode는 Main Control Unit으로 들어간다.

> Main Control Unit
Main control은 opcode (I[6-0])을 input으로 받는다.
이를 이용해 instruction의 대략적인 type을 판별하고, 총 7가지(총 8-bit) 신호를 출력한다.
(mux에 총 3-bit, RegFile에 1-bit, Data Mem에 2-bit, ALUOp로 2-bit 해서 총 8-bit)
(funct도 opcode의 연장선이긴하지만, 여기선 ALU Control Unit에서만 쓰임.)

※ 정리
뭔가 내용이 많았는데 결국은

전부 얘를 자세하게 설명하기위한 것들이다.
그러니 세부사항 잘 이해하고,
저 그림 그대로 따라그릴 줄 알고(control 선이랑 instruction bit width 들어가는거랑 각 회선 bit width 전부 포함해서),
instructions마다 control 신호(ALU control 포함) 어떻게 되는지 알면... 뭐 그 정도면 될 것 같다.
<참고>



Q. Why Single-cycle Implementation is not Used Today?
A. 현대 designs에서 사용하기엔 매우 비효율적이라서 그렇다.
1) single-cycle 방식에선 processor 내에서 가장 긴 path에 맞춰서 clock cycle을 결정해야한다. 무슨 말이냐면 모든 inst가 한 cycle안에 다 수행돼야하니 clock cycle은 가장 긴 path에 맞춰져야한다. 초반에도 말했지만, 특정 state element에서 다음 state element로 가기까지 1 cycle안으로 돼야하니 그 사이 comb가 너무 복잡해선 안된다. 반대로 말하자면, comb가 이미 결정돼있다면 우리가 cycle을 길게 해줘야 한다.
이렇게 해버리면 굳이 느리게 할 필요가 없는 instructions도 가장 오래 걸리는 instruction에 맞춰지니 전체적으로 느려진다.
(예를들어 위에서 지금까지 본 Datapath는 load inst의 path가 가장 길다. 얘 때문에 나머지도 다 느려진다.)
2) 그렇다고 clock period를 inst마다 다르게 할 수도 없다. 매번 다르게 한다는게, 언제 어떤 구간을 줘야하는지 예측도 어렵고 실현도 불가능하다.
3) 결국 Single-cycle 구현 방식은 worst case에 모든 것들이 맞춰지므로 "Making common case fast"라는 design principle을 따르더라도 아무 소용이 없을 수 있다. 즉, Single-cycle은 이 원리를 위반하는 구현 방식이다.
'수업 > Computer Architecture' 카테고리의 다른 글
| [Computer Architecture] Processor - 2 (0) | 2022.12.15 |
|---|---|
| [Computer Architecture] Memory Hierarchy (0) | 2022.10.20 |
| [Computer Architecture] Arithmetic for Computers(2) (2) | 2022.10.18 |
| [Computer Architecture] Arithmetic for Computers(1) (0) | 2022.10.13 |
| Language of the Computer (5) | 2022.09.14 |